やりたいこと
SharePointで指定フォルダ直下の全てのエクセルテーブルの表を一か所に集約する。
例えば、店舗A、店舗B、店舗Cなどの売り上げ情報が店舗ごとに1ファイルにまとめられているとする。
売上の集約にはOffice Scriptを使いたいが、スクリプトは別のエクセルファイルを読み込むことができないので、Office Scriptでデータを参照するための全段階として今回の集約作業をPower Automate のクラウドフローで実装する。
実装フロー
変数定義
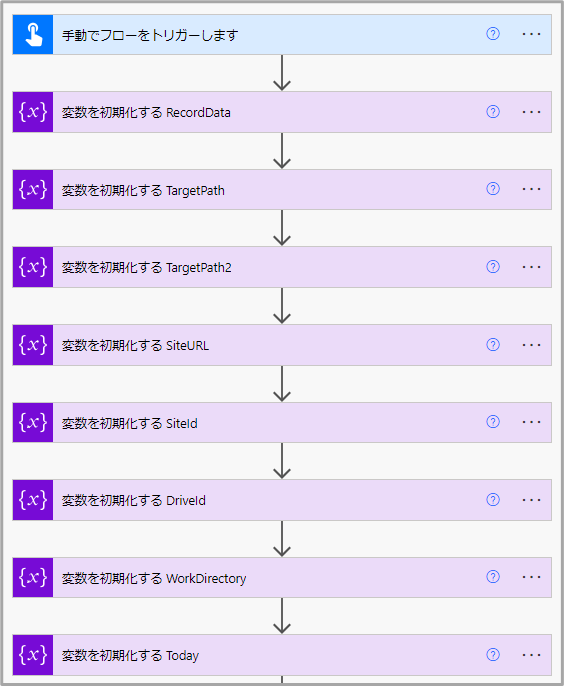
それぞれの変数の利用用途と初期値を以下に示す。
// 集約テーブルに追加するためのデータを格納するArarylet RecordData = [];
// インポート対象の各ファイルのパス
let TargetPath = "";
// インポート対象の各ファイルのパス(ドキュメントのパスを除いたもの)
let TargetPath2 = "";
// シェアポイントサイトのURL・サイトID・ドライブIDを定義
// 再利用性向上のために利用
let SiteURL = "★★★";
let SiteId = "";
let DriveId = "";
// 集計対象ファイルの格納されるフォルダへのパス
let WorkDirectory = "/Shared Documents/テイルズクイズ/回答";
// 本日日付
let Today = ""
現在日付の取得
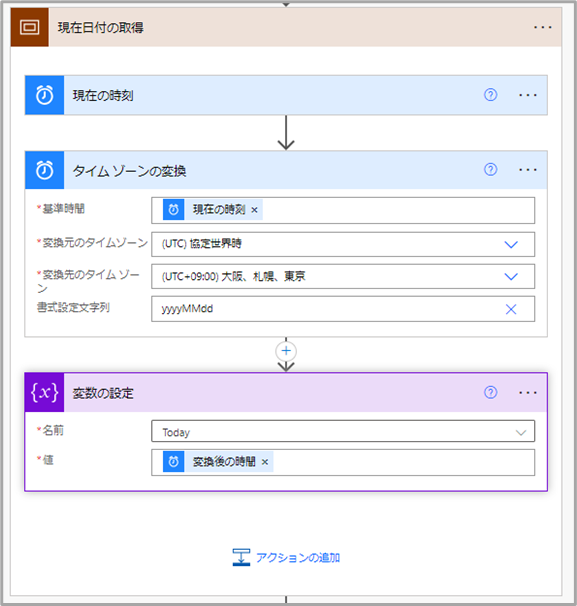
Power Automate に慣れているのであれば、コネクタでなく関数を使ってそのまま現在日付を初期化したほうが楽かもしれない。
サイトID・ドライブIDを取得
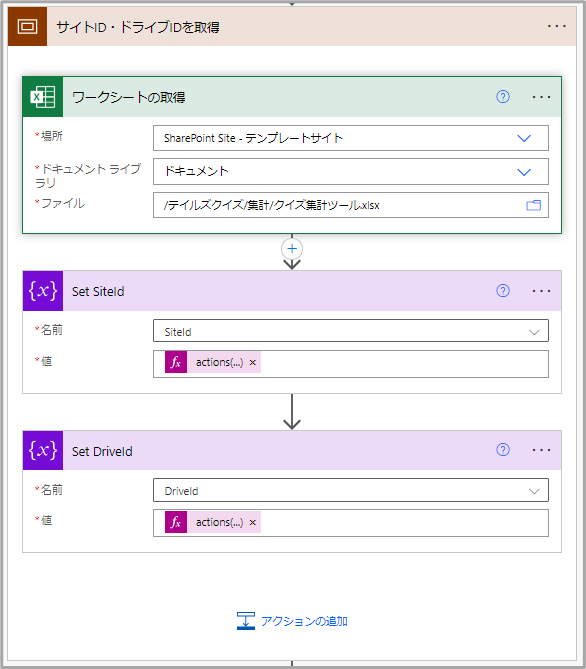
エクセルファイルの参照をする際にサイトIDとドライブIDが必要になるため、あらかじめ取得しておく。Share Point Rest APIを使えば、それぞれ取得できるようだが、少し難易度が高かったため、暫定的に楽な方法を採用。
コネクタにそれぞれの値を固定値で設定すれば、後続のコネクタで参照することができる。ゆえにワークシートを取得すること自体に意味はない。(サイトIDとドライブIDが分かるコネクタであればなんでもよい。)
SiteId = @{actions('ワークシートの取得')?['inputs/parameters/source']}
DriveId = @{actions('ワークシートの取得')?['inputs/parameters/drive']}フォルダ一覧の取得
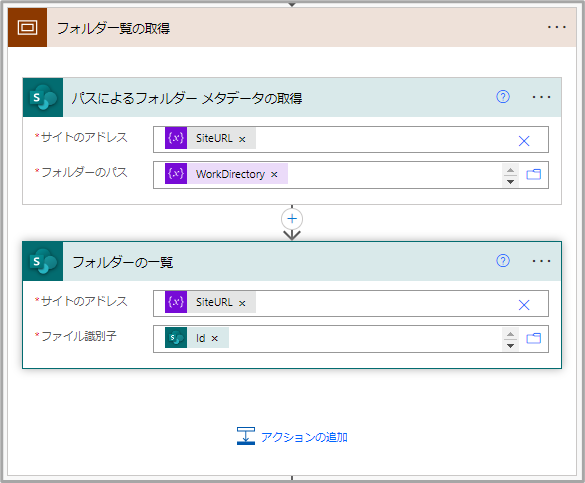
インポート対象のファイルを列挙している。
せっかくSiteIdを取得しているのに別途SiteURLの変数も用意しているのは少し格好が悪いので、片方だけで済むように改善したい。
ファイル数分繰り返し
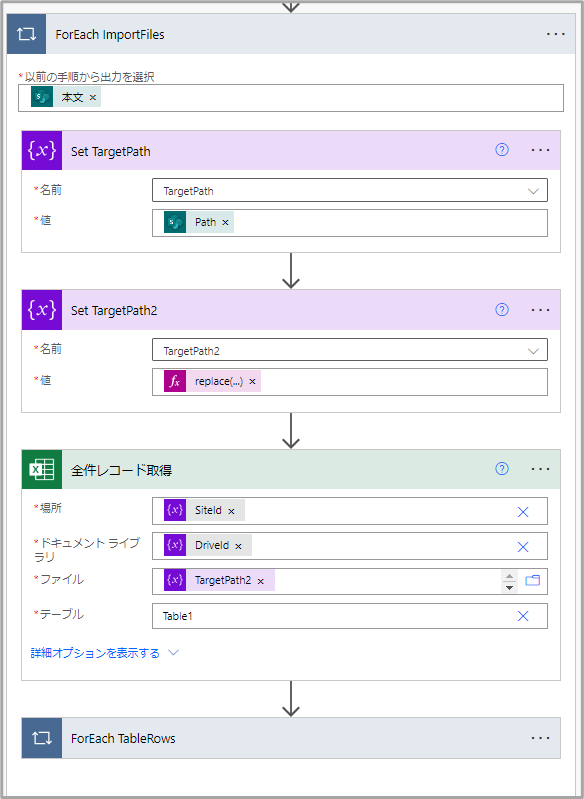
TargetPath = @{items('ForEach_ImportFiles')?['Path']}
Targetpath2 = @{replace(variables('TargetPath'), '/Shared Documents', '')}トリガー:全件レコードでは、パスの頭に「/Shared Documents」を付けると怒られるため、取り除いている。また、今回はあらかじめテーブルの名前が「Table1」であることを前提としている。
もし、テーブル名がバラバラであったり、1ファイル中に複数のファイルがある場合は、テーブル名を動的に取るために「テーブルの取得」コネクタを呼び出す必要がある。
その場合、現在の2重ループから3重ループになるため、結構しんどい。
出力判定
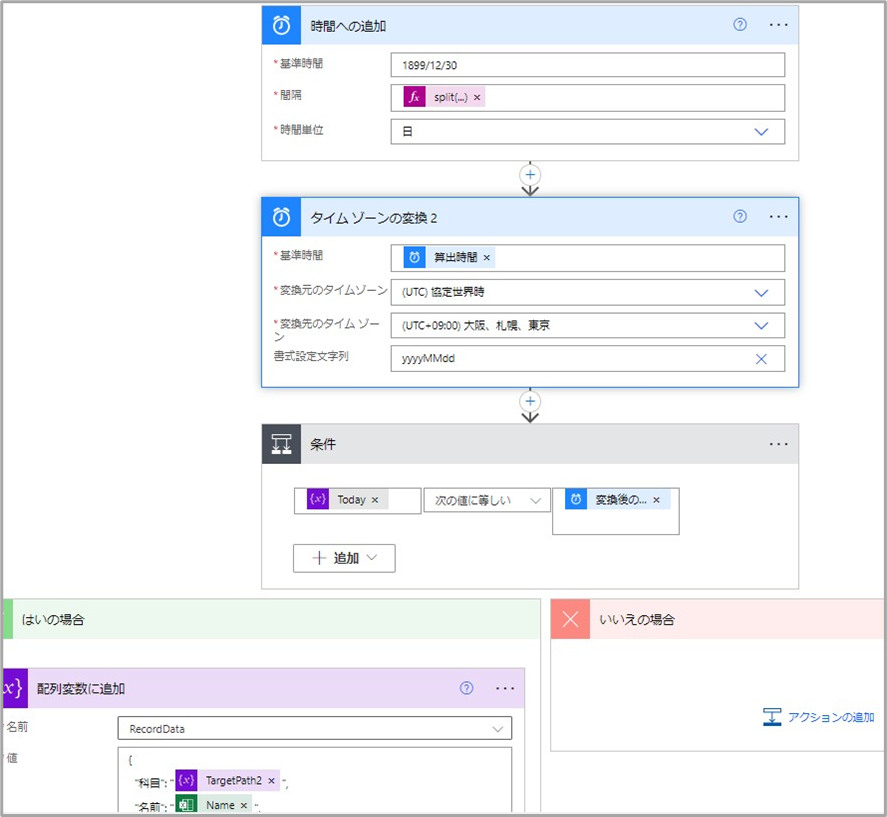
「全件レコード取得」コネクタで取得した行を集約テーブルに追加するかの判定をする。本当は集約テーブルをクリアにしてから、全件追加するのが楽なのだが、0.5件/秒とめちゃめちゃ重いため、日付が一致する(一日当たりの)行のみを追加している。
//「時間への追加」コネクタ
// 間隔
interval = @{split(items('ForEach_TableRows')?['Completion time'],'.')[0]}
// 「配列変数に追加コネクタ」
value = {
"科目": "@{variables('TargetPath2')}",
"名前": "@{items('ForEach_TableRows')?['Name']}",
"回答日": "@{items('ForEach_TableRows')?['Completion time']}",
"点数": "@{items('ForEach_TableRows')?['Total points']}"
}intervalでわざわざsplit関数を用いているのは、string型をint型にキャストできないため。なんてこった。
valueにおける連想配列のキー値は集約テーブルの列名と一致させている。
こうすることで、自動的に名前が一致する列に値が出力される。
集約テーブルへの書き出し
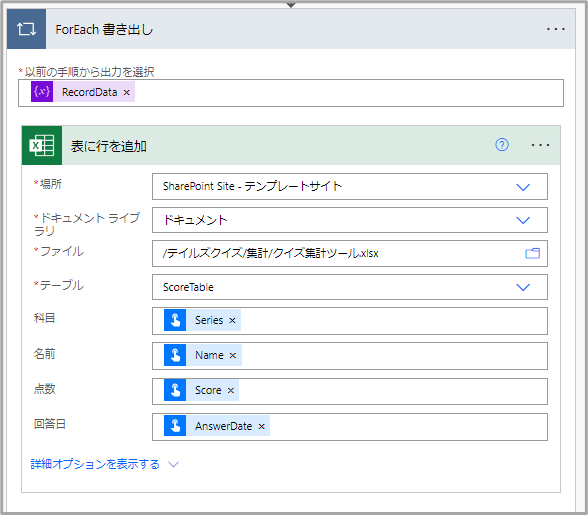
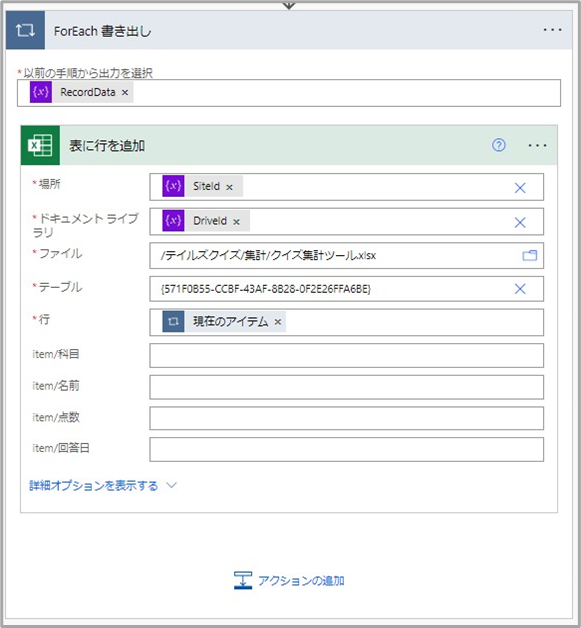
この記事を書いている最中に、最後だけSiteIdとDriveIdを設定していなかったことに気が付いたので、以下のように編集。
するとファイル名と、テーブルIDも固定値になっていることに気が付く。
全て変数にするのであれば、ファイル名については、ファイルパスからファイル識別子を取得し、テーブルIDはテーブル取得コネクタを利用し、変数に定義したテーブル名の一致するものを設定するという流れになるかと思うが、あまりにも血が流れすぎてしまうので、いったんはこれでいいかという形で記事を残す。
ちなみに下4行にitem/xxxと表示されているのは、フローの画面を開きなおしたら消えていた。
反省点
単純に処理が遅い。0.5件/秒程度で行が挿入されるため、1000件の場合500秒≒9.5分。
ちなみに0.5件/秒というのは15件程度でテストした場合の話であり、100件にしたところ3分ほどかかった。
件数と時間はきれいに比例せず、件数に応じて、どんどん重くなっていくようだ。
となると、1000件の場合、30分程度かかる可能性もある。(検証はしていないが)
取得したデータはPower Automateで処理をせず、丸ごとOffice Scriptに丸投げし、
getRange().setValues()で一括出力したほうが良さそうだ。