もくじ
やりたいこと
Azure が提供しているAIサービスを利用して、テキスト分類を行う。
テキスト分類とは、今日は洗濯物が乾きやすそうだ→「晴れ」、傘が必要だ→「雨」というもの。
一連の流れ
- 学習データの作成
・学習データの用意
・学習データのテキストファイル変換 - Azure AI Language リソースの作成
- Azure ストレージアカウントの作成
・AI Language リソースのロール割り当て
・CORSの定義追加
・学習データのアップロード - JSONファイルでテキスト分類プロジェクトを作成
- モデルの学習
- モデルのデプロイ
- モデルのテスト
1.学習データの作成
学習データの用意
まず学習させたいテキストを一覧として列挙する
Language Serviceでは次の登録方法が用意されている。
- 「アップロード後、1件ずつカテゴリを登録をする」
- 「アップロード後、ChatGPTの自動カテゴリ機能を利用する(有料)」
- 「JSONファイルをimportすることでアップロードとカテゴリ登録を一度に行う」
どうやら、テキストデータとカテゴリを列に持つcsvファイルをアップロードする機能が設けられていないようだ。今回は登録方法3.で進めていく。
また、利用するデータは、電話でのお問い合わせに対して、「どういった問い合わせであったか」をカテゴリとしている。

学習データのテキストファイル変換
学習データ1件(エクセルの1行分)につき1つのテキストファイルとして出力する。
バッチのechoコマンドを利用して、ファイル出力をしている。
Shift-JISでなくUTF-8として出力をしたいので、echoコマンドを実行するまでに「chcp 65001」を叩いておく。
chcp 65001
="echo """& "【質問】" & D2 & "【回答】" & E2 &""" > "&$M$1&G2

2.Azure AI Language リソースの作成
Azure ポータルへログインする
「リソースの作成」 > 「AI + 機械学習」 > 「言語サービス」を選択
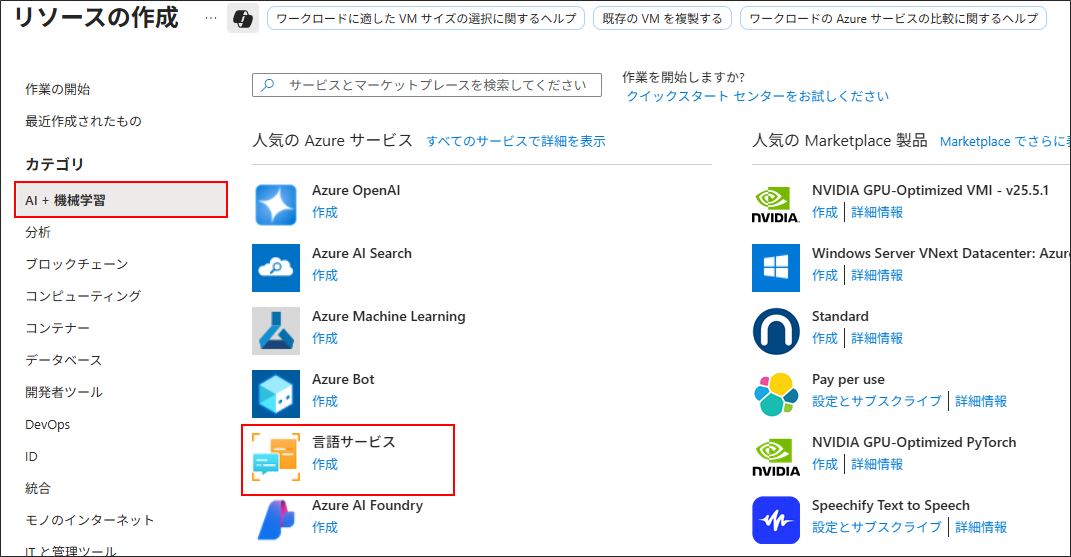
「リソースの作成を続行する」をクリック
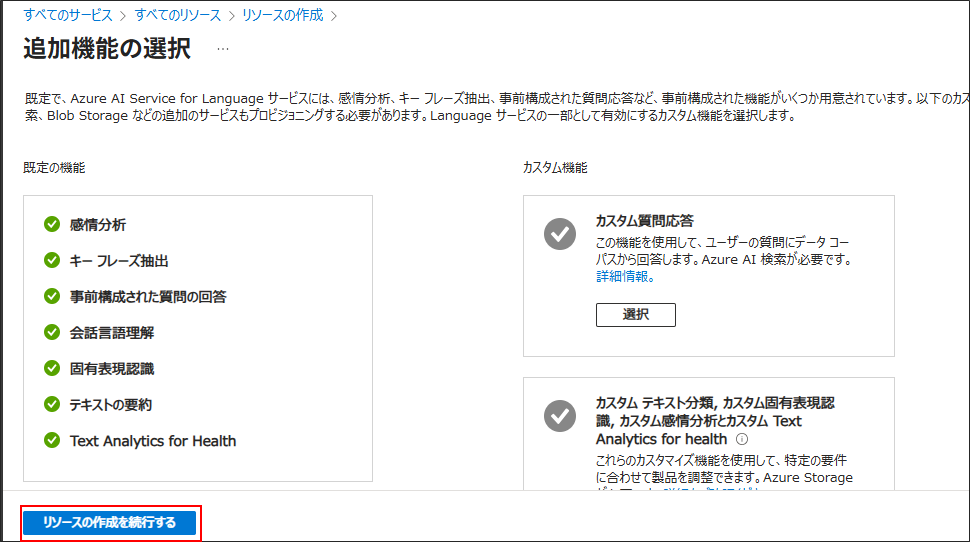
赤枠内を一通り入力 & 選択してから、「確認と作成」をクリック
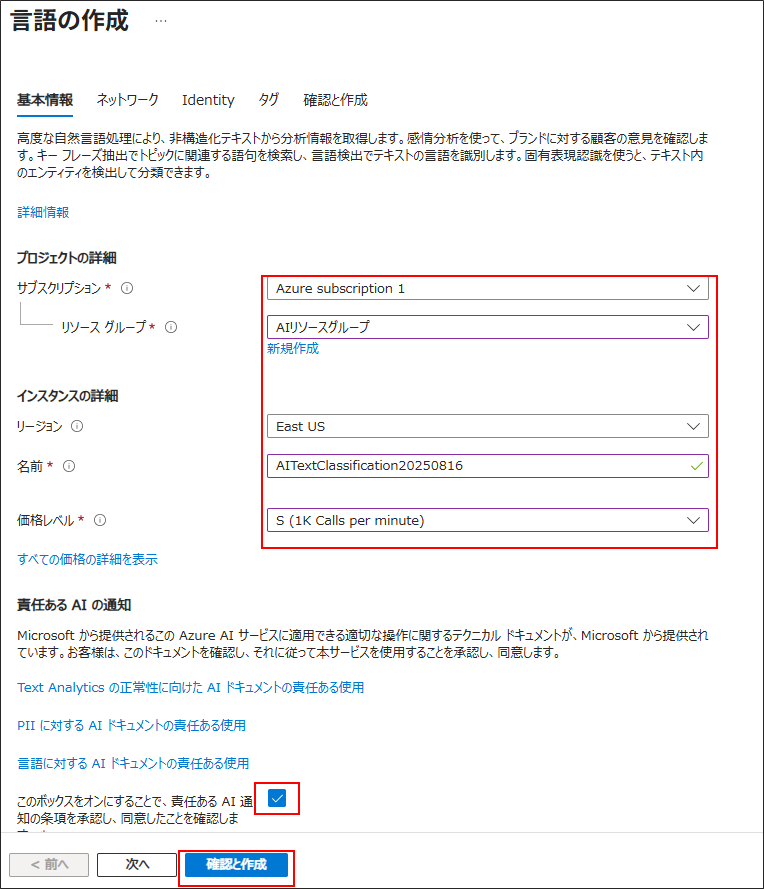
リージョンについて
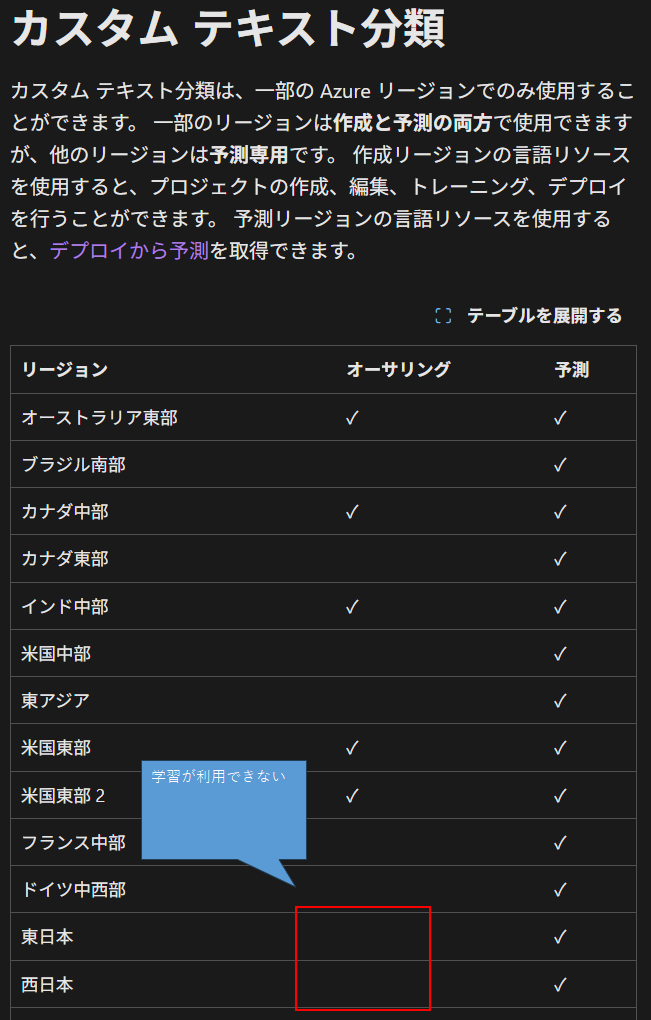
ここで、リージョンに「Japan」を選んではいけない。
テキスト分類AIは「公開前の学習」と「公開後の利用」があるが、一部のリージョン(地域)では「公開前の学習」機能が利用できない。
仮に、「Japan」を選んだ場合、「あなたのリージョンでは利用できません」という旨のメッセージがLanguage Studioの画面に表示される。
学習が利用できるかはMicrosoftを(Language サービスでサポートされているリージョン)参照。
3.Azure ストレージアカウントの作成
学習データをAzure上に保存するためのストレージを用意する。
「リソースの作成」 > 「ストレージ」 > 「ストレージアカウント」をクリック
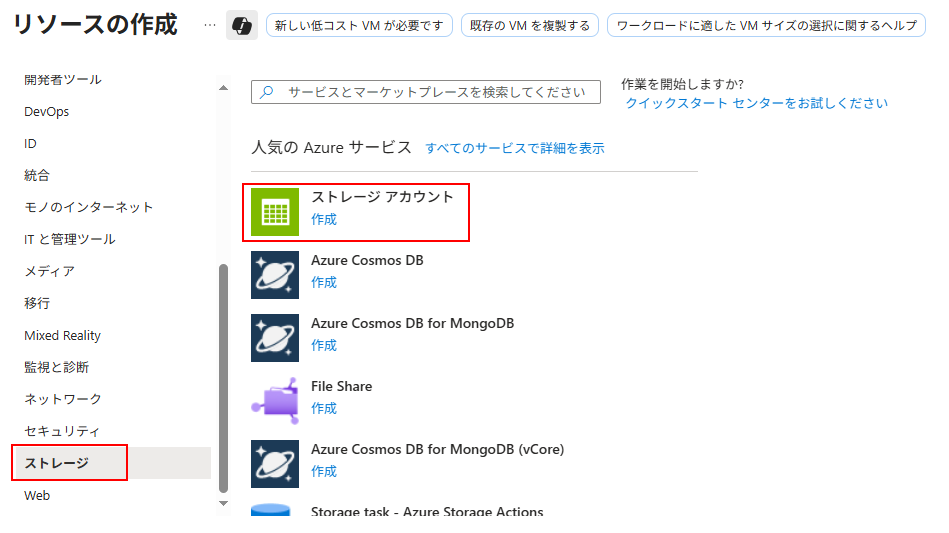
サブスクリプション、リソースグループ、リージョンは「Azure AI Language」と同じものを選択する
プライマリサービスには「Azure Blob Storage または~」を選択する
「レビューと作成」をクリック
ストレージアカウントが作成されたら、アカウント名のリンクをクリック
AI Language リソースのロール割り当て
作成したストレージを「AI Language」が利用できるようにロールを割り当てる
「アクセス制御(IAM)」 > 「+ 追加」 > 「ロールの割り当て」を選択
検索窓に「BLOB」と入力して「ストレージBLOBデータ所有者」を選択
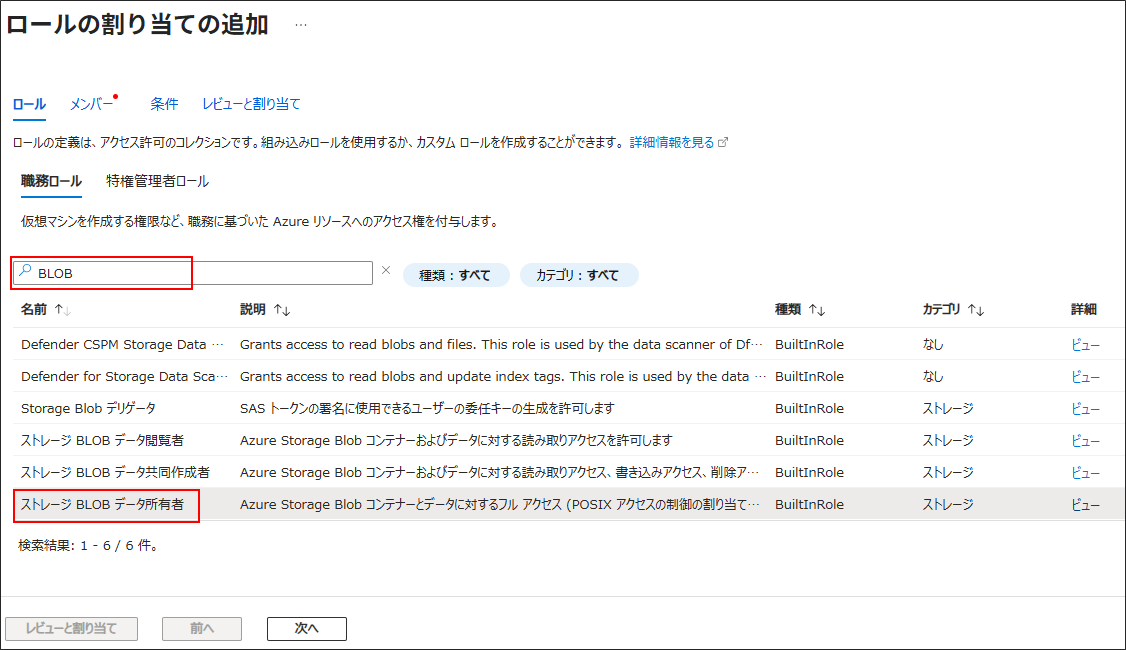
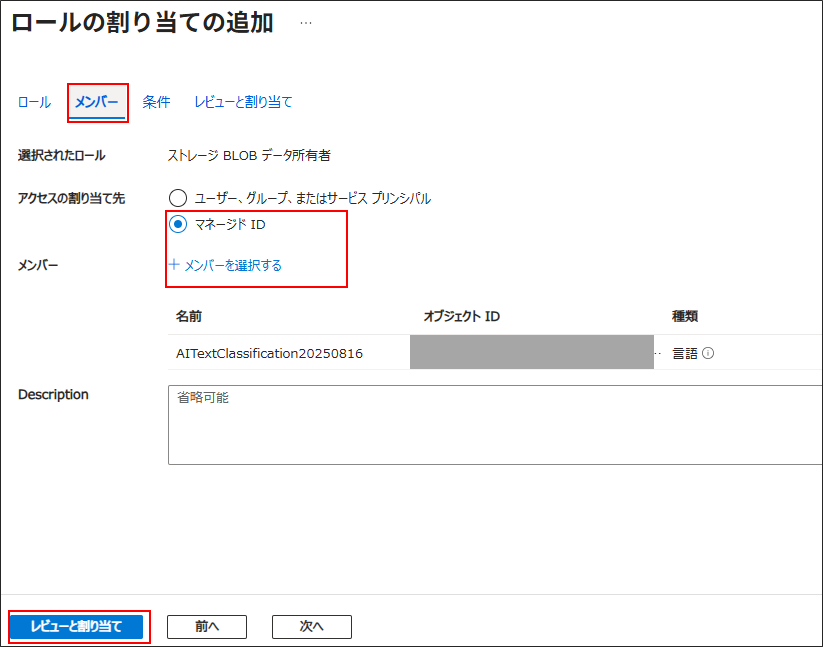
「メンバー」 > 「マネージドID」 > 「+メンバーを選択する」にてAzure AI Languageリソース(AITextClassification20250816)を選択
「レビューと割り当て」をクリック
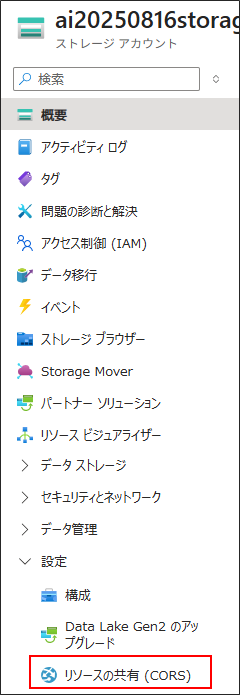
CORS (Cross-Origin Resource Sharing)の定義を追加
作成したストレージに対して、「どのサイトからであればアクセスを認めますよ」の定義を加える
ストレージアカウント > 「リソースの共有(CORS)」を選択
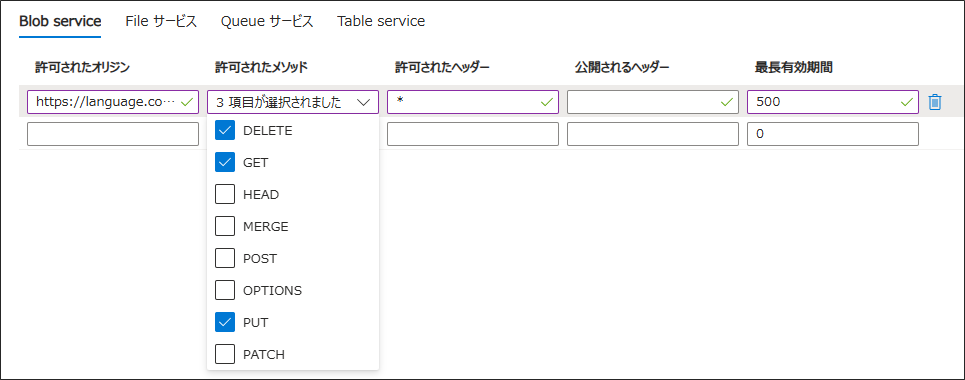
「許可されたオリジン」に「https://language.cognitive.azure.com」を設定する
他の項目についても、図の通り設定する
{kind=link}
学習データのアップロード
「1.学習データの作成」で用意したテキストファイルをAzure ストレージにアップロードする
ストレージアカウント > 「概要」 > 「アップロード」 >「新規作成」で適当なコンテナを作成
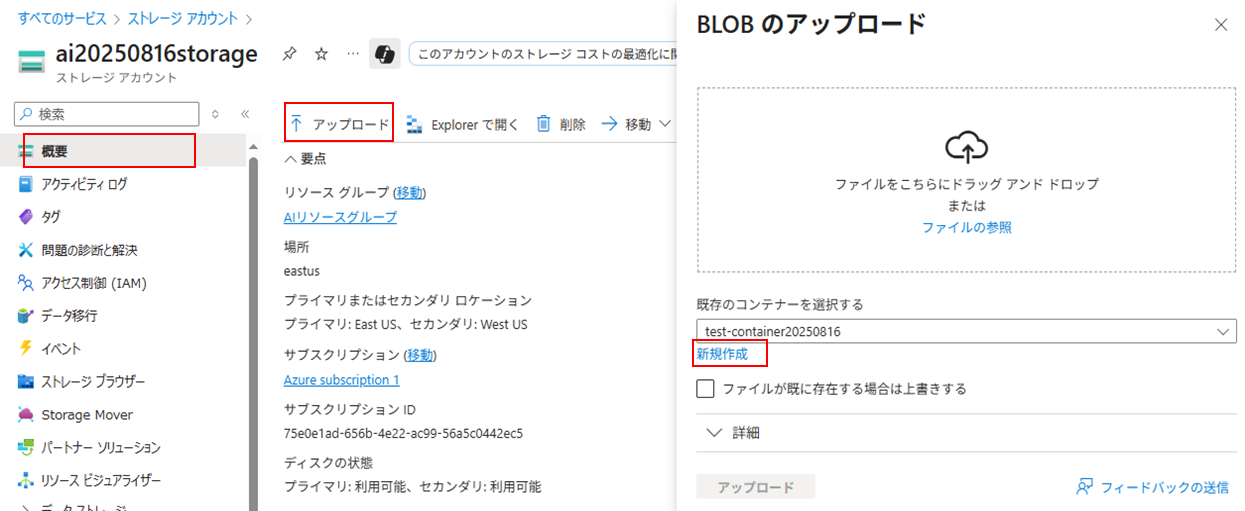
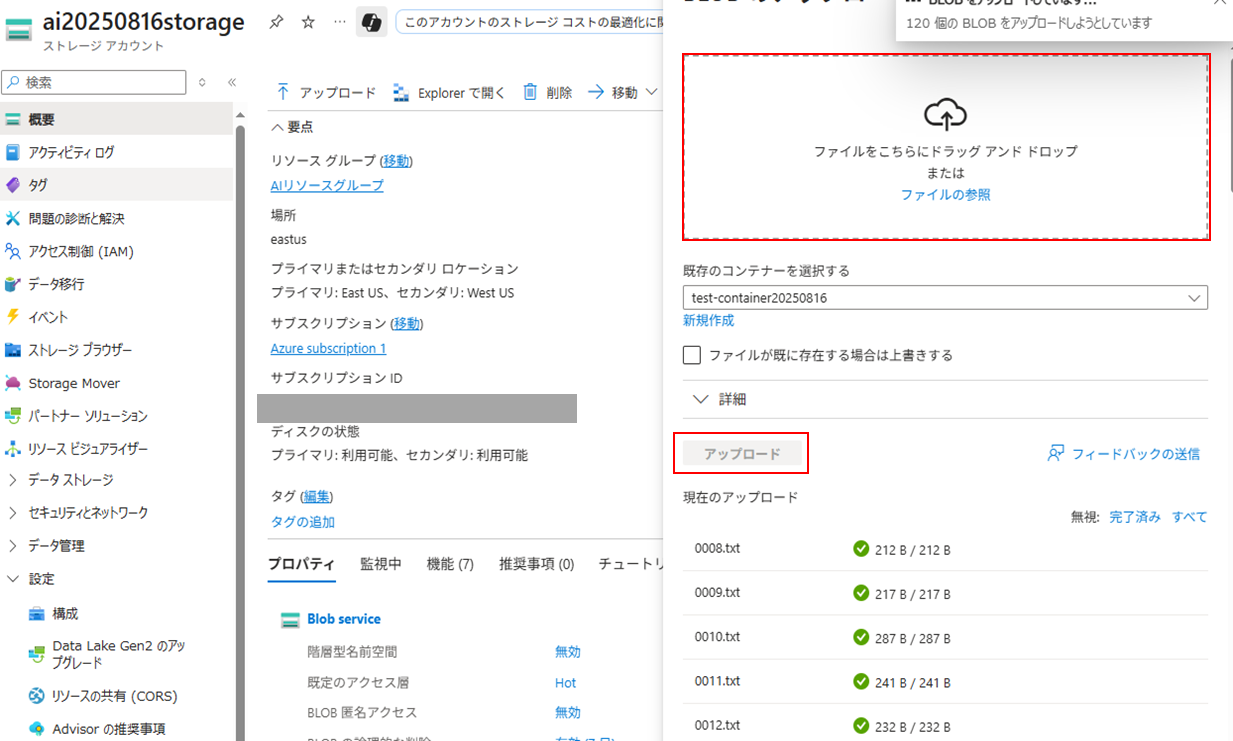
テキストファイルを一括ドラッグ&ドロップし、アップロードボタンをクリック
4.JSONファイルでテキスト分類プロジェクトを作成
JSONファイルの作成
プロジェクトを作成するためのJSONファイルのフォーマットは公式HP(クイックスタート: カスタム テキスト分類(REST API))を参照
{property-name}に必要情報を設定していく
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customSingleLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customSingleLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"class": {
"category": "Class2"
}
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"class": {
"category": "Class1"
}
}
]
}
}
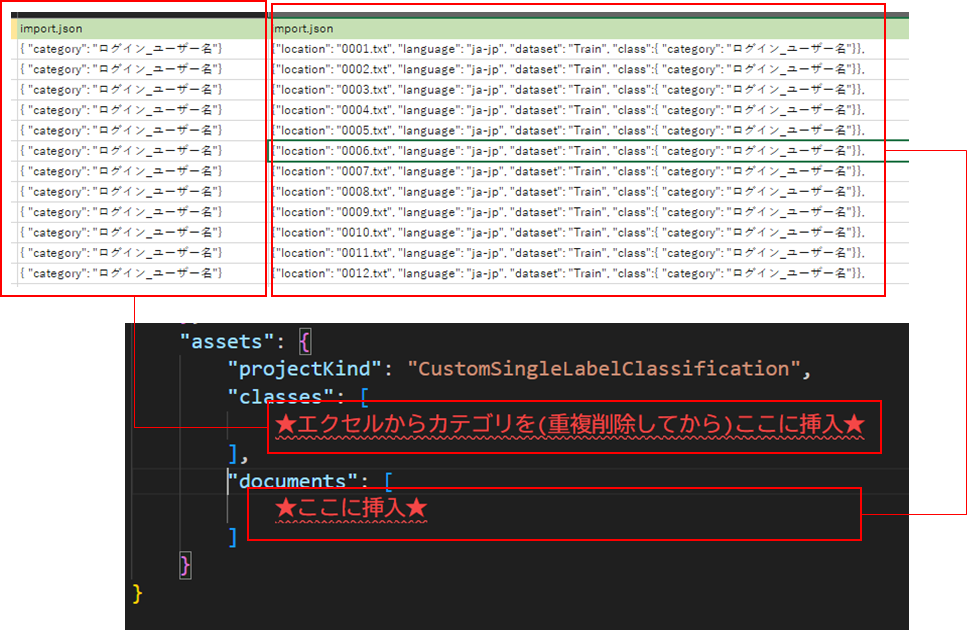
classesとdocumentsはエクセルの関数を使いつつ、いいかんじに加工して挿入していく。
// classes
="{ ""category"": """&F2&"""}"
// documents
= "{""location"": """ & G2 & """, ""language"": ""ja-jp"", ""dataset"": ""Train"", ""class"":" & H2 & "},"
Language Studioの言語設定
ようやく全ての事前準備ができた。
Language Studioへログイン
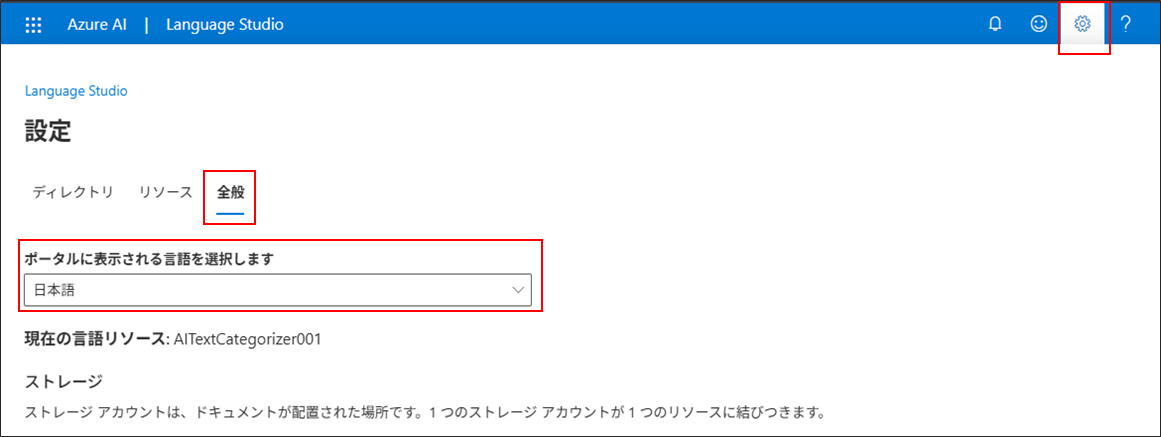
右上の⚙マークから日本語を設定
JSONファイルのインポート
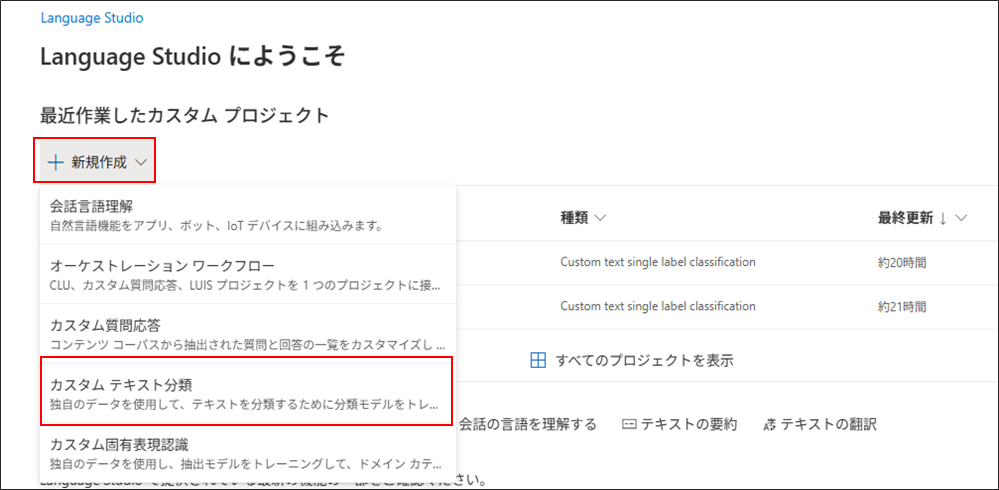
ホーム画面で「+新規作成」 > 「カスタムテキスト分類」を選択
初めての利用の場合、サインインが必要だったかも
サインイン後、Azure のサブスクリプションやリソースグループの入力が求められたら、「1.Azure AI Language リソースの作成」と同じものを選択する。
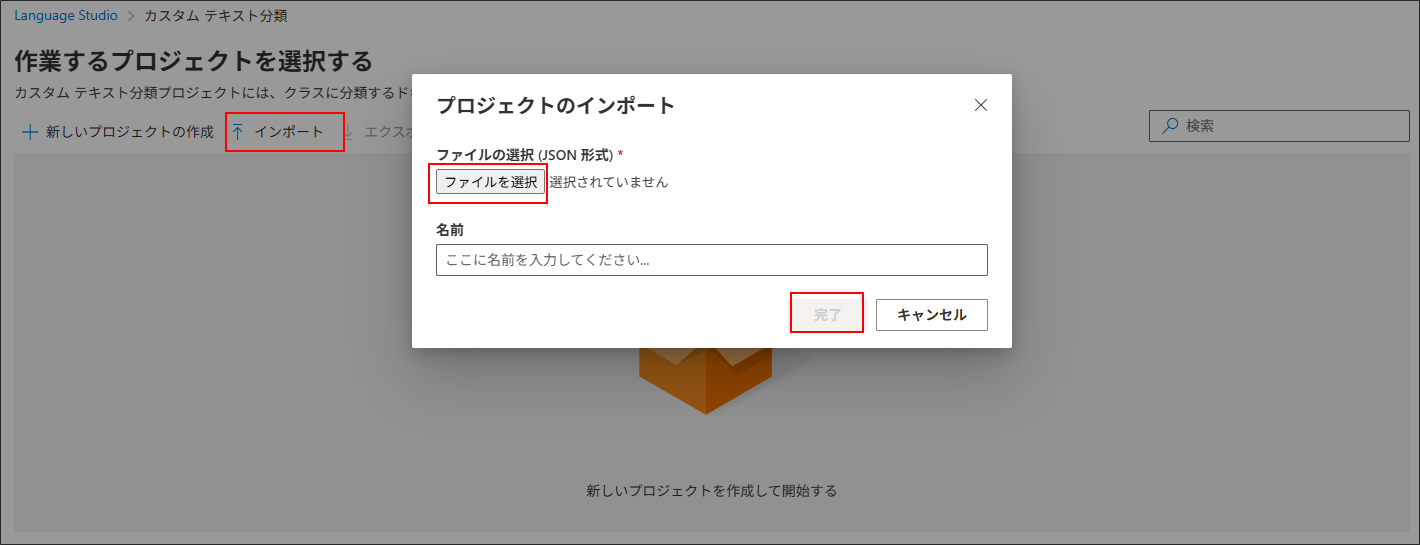
「インポート」 > 「ファイルを選択」 > 「完了」を選択
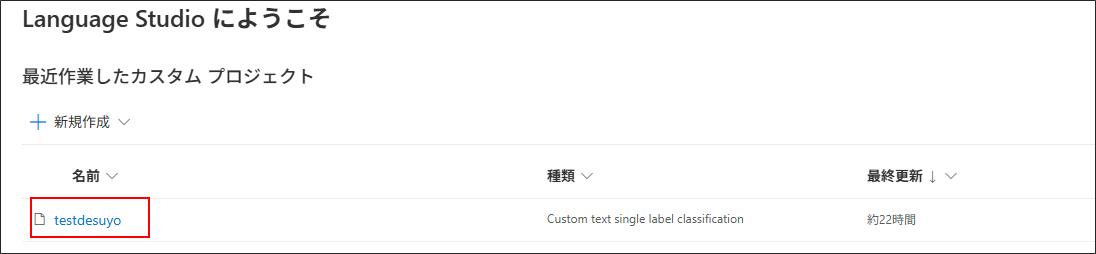
インポートが完了したら、プロジェクト名のリンクを選択
5.モデルの学習
モデルを学習させるために、以下の手順を実施する。
「トレーニング ジョブ」 > 「+トレーニング ジョブを開始する」を選択
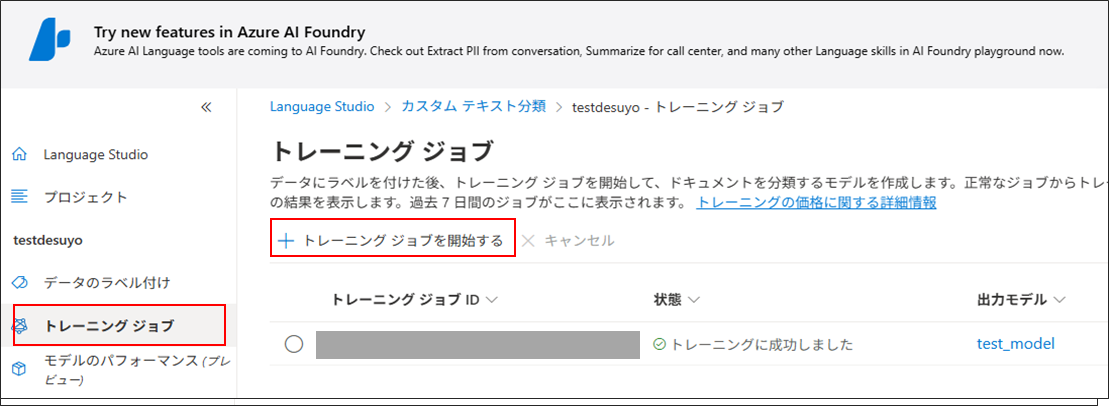
任意のモデル名を入力し、「トレーニング」ボタンをクリック
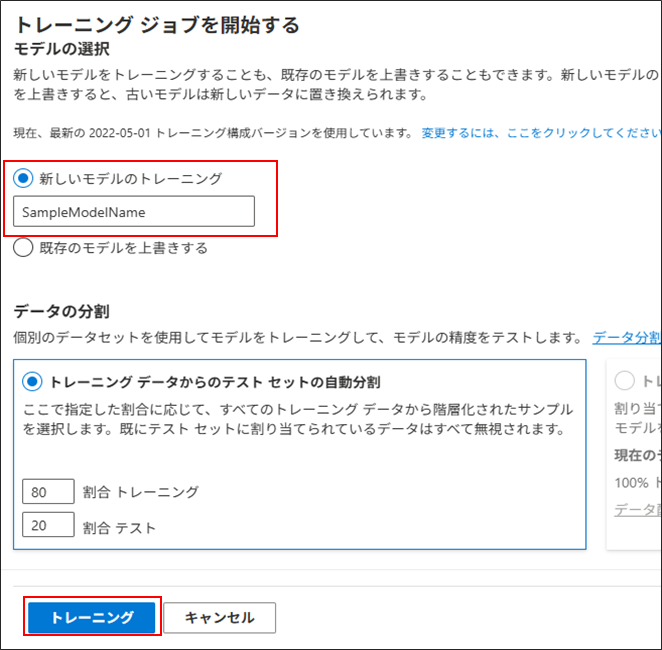
6. モデルのデプロイ
学習したモデルを外部 (Power Automateや他のサイト)からアクセスできるように、デプロイを行う。
「モデルのデプロイ」 > 「デプロイの追加」 > デプロイ名の入力をして、「デプロイ」ボタンをクリック
下記のように作成されたデプロイ名が表示されればOK
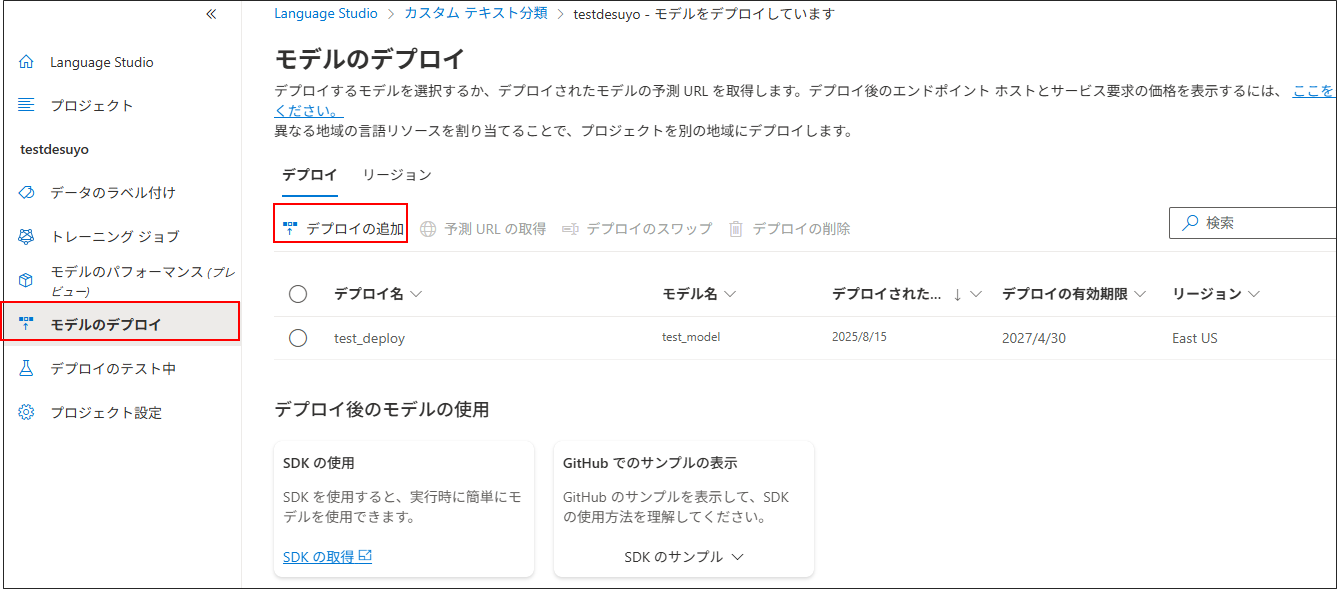
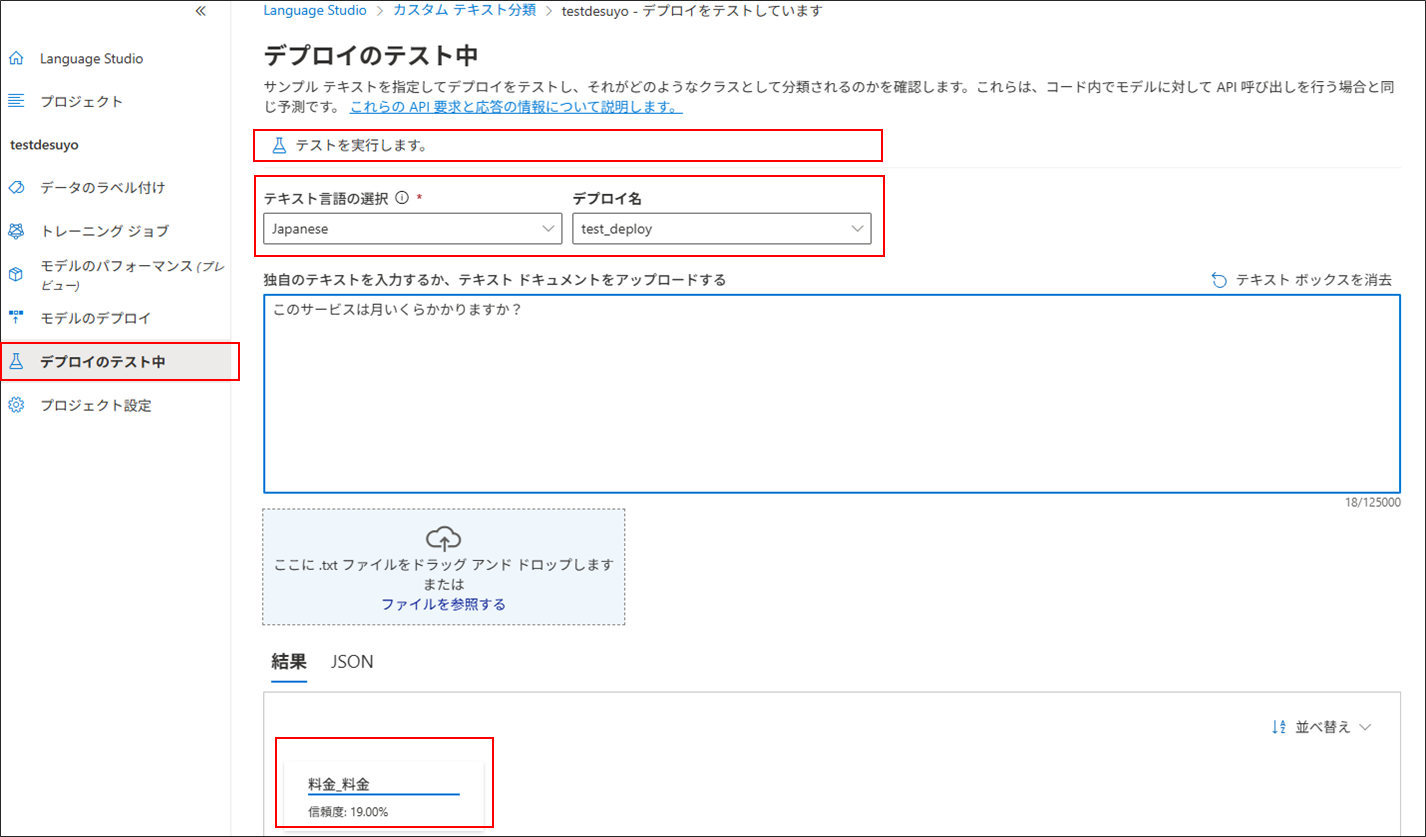
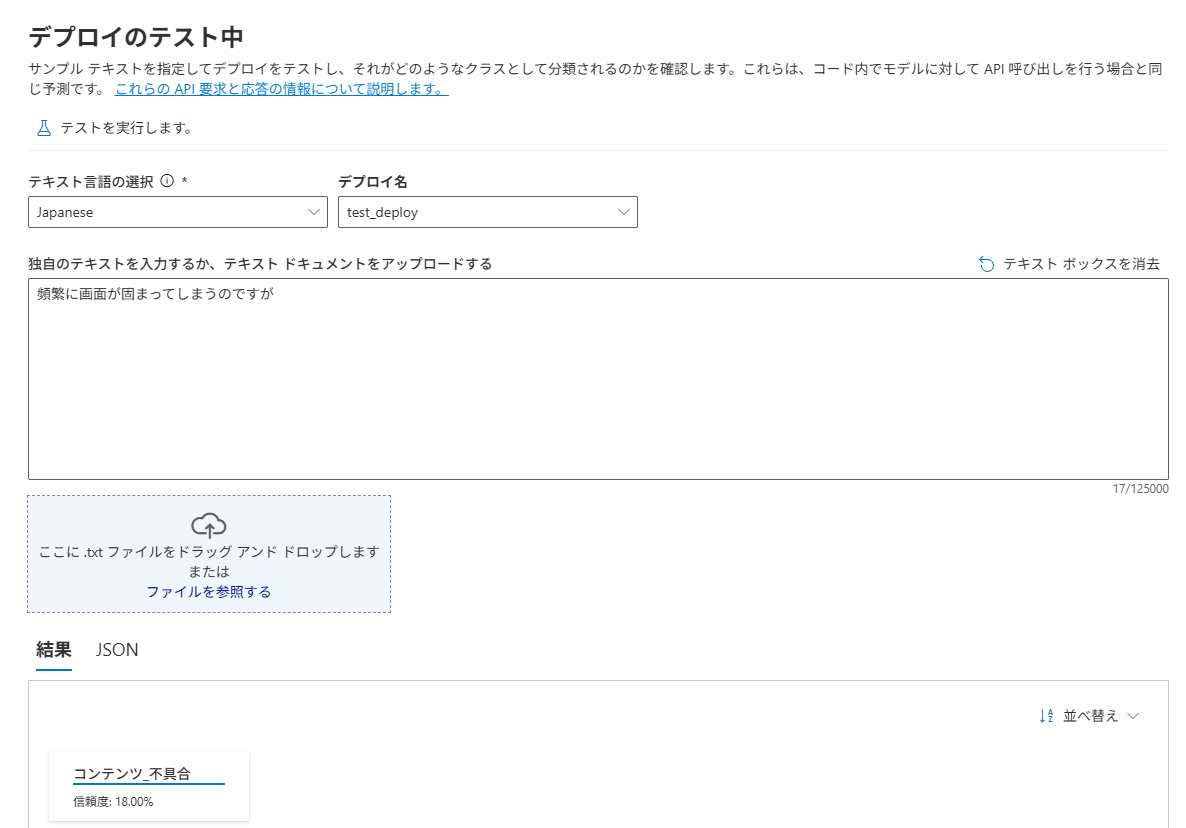
7.モデルのテスト
「6.モデルのデプロイ」までできたら、設定作業は完了
あとは、テキスト分類が正常に動作するかについても、画面上から即座に確認をすることができる。
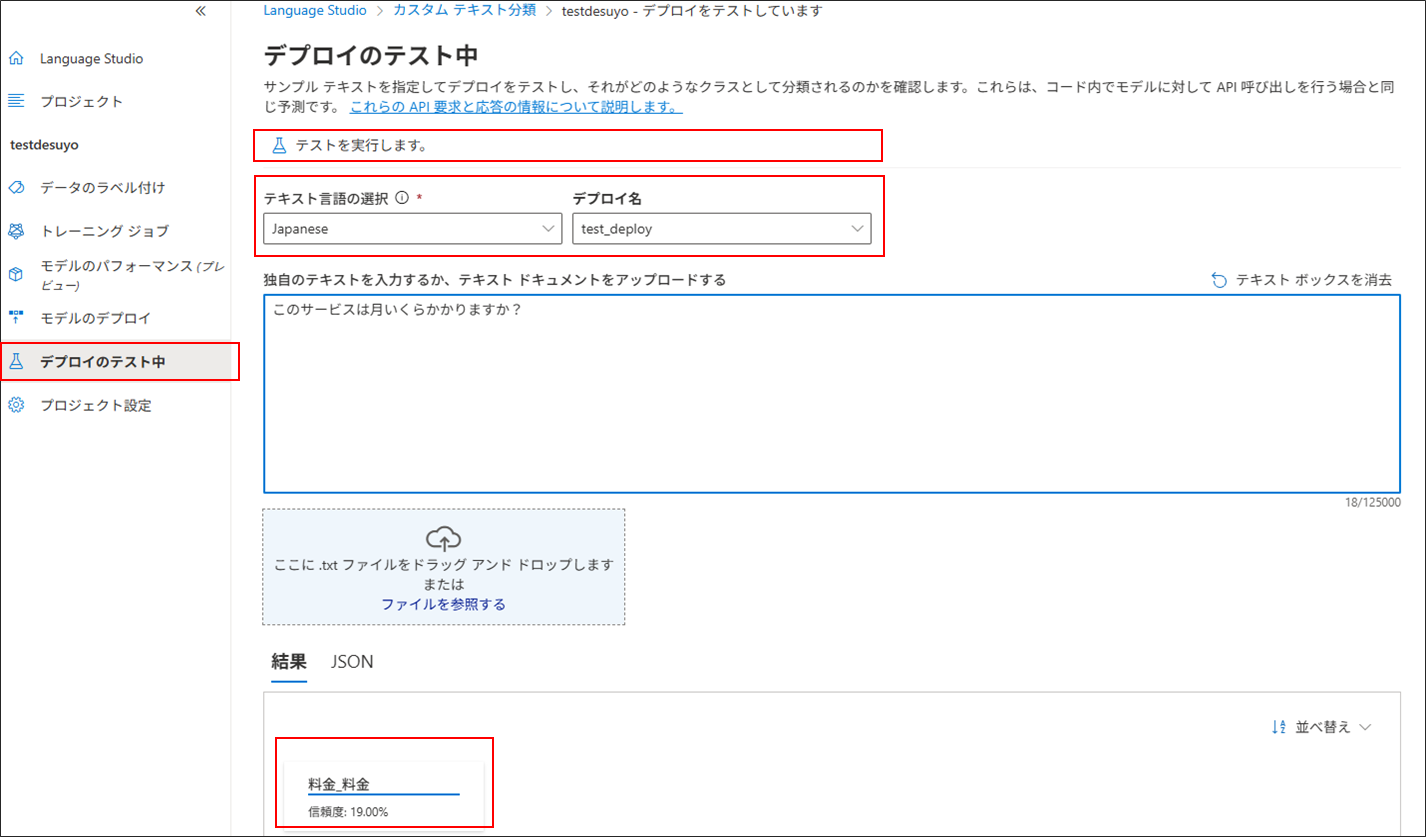
「デプロイのテスト中」 > 「テキスト言語とデプロイ名」を選択 > 分類したいテキストを入力し、「テストを実行します」を選択。
分類が完了すると、分類結果が画面下部に表示される。
トラブルシューティング
リージョンを許容できるか
企業には、国内でしかデータを管理させないというような運用をしているところがあるので、
海外にデータを置いても問題ないかはよく確認をする必要がある。
ストレージの切り替えがうまくいかない場合がある
Language Studioの制約で、「Azure AI Language リソース」と「Azure ストレージ」は1 : 1でしか紐づけが出来ない。
そのため、新しいストレージを作成した場合、合わせてAzure AI Language リソースも作り直す必要がある。
Language Studioの画面上で、「Azure AI Language リソース (A → B)」を変更しても、「Azure ストレージ」がうまく切り替わらず、前に作成した「Azure AI Language リソース(A)」に紐づくストレージのみ表示されることがある。
その場合は、面倒だが、「Azure AI Language リソース (A)」を削除すると解決する場合がある。
リソース作成の反映にはラグがある
Azure上で「Azure AI Language リソース」と「Azure ストレージ」を作成しても、Language Studioから参照するには時間がかかる場合がある。
例えば、ロール付与や、CORSの設定をしても、「ロールが割り当てられていません」や「CORSの設定がされていません」など。
気長に、待ちましょう。