もくじ
取得したKintoneレコードを扱う際の3つの問題点
REST APIを通じてKintoneからjson形式でレコードを取得することができる。
{
"records": [
{
"order_received_date": {
"type": "DATE",
"value": "2025-09-18"
},
"レコード番号": {
"type": "RECORD_NUMBER",
"value": "47"
}
}
}
そして、それぞれのフィールドにアクセスするときの式の書き方は以下の通り
// 3件目のレコードのフィールド「order_received_date」の値を参照
@body('HTTPのアクション名')['records'][2]['order_received_date']['value']
for each内で参照をする場合
@items('Apply_to_each')['order_received_date']['value']
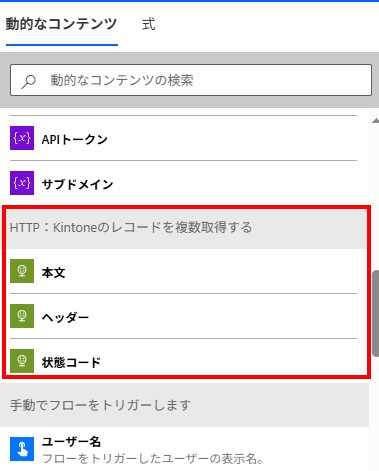
問題点1. 動的なコンテンツ上からフィールドを指定できない
Kintoneから取得したレコードに限ったことではないが、アクションの出力結果の詳細は大抵、GUI上からフィールドを選択することが出来ない。
つまり、フィールドに参照をするたびに上記参照式を手入力しなければならないということになる。
これを一般的なプログラミング言語に置き換えると、「定数化」が出来ていない状態ではないか。
問題点2. フィールドへのアクセスが複雑である
Kintoneのフィールドアクセスに対して複雑であるというのは過言かもしれないが、Kintone以外のサービスではもっと複雑なJSONが返却されるかもしれない。そうすると、やはり式の組み立てをする際にJSONの構造を常に意識する必要があり、実装に時間がかかってしまうことになると思う。
そのため、取得したJSONは以下のように階層1のフラットなJSONに変換できたらよい。
{
"records": [
{
"order_received_date": "2025-09-18"
, "レコード番号": "47"
}
}
問題点3. JSONの構造定義の変更に弱い
あまり意識する必要がないことではあるが、極端な話、valueのキー名がvaluevalueに置き換わったら、Kintoneのフィールドを参照している全ての式を修正する必要がある。
そのため、取得したフィールドの結果については、JSONの構造を知る必要なくアクセスできる術が必要である。
■変更前
{
"records": [
{
"order_received_date": {
"type": "DATE",
"value": "2025-09-18"
}
}
}
■変更後
{
"records": [
{
"order_received_date": {
"type": "DATE",
"valuevalue": "2025-09-18"
}
}
}
問題1 ~ 3に対する改善案
改善案1. 「JSONの解析」アクションを利用する
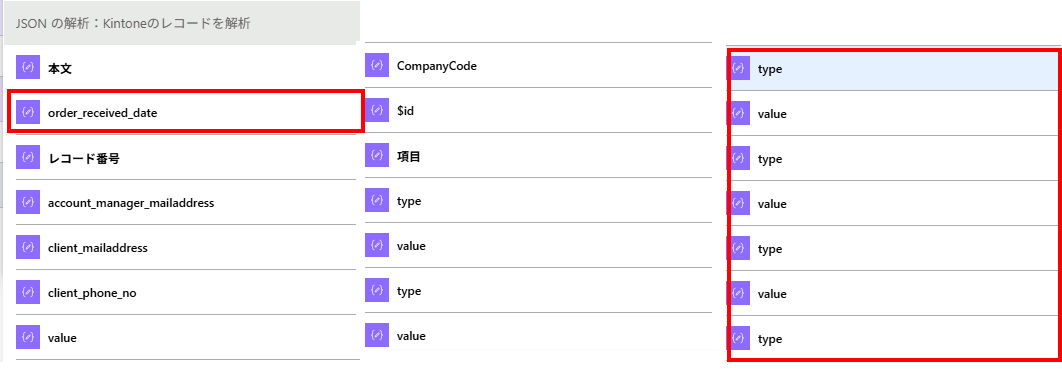
「jsonの解析」アクションを利用することで、確かに動的なコンテンツ上から「フィールド名」を参照することが出来た。
フィールド名を選択しても、その中身は「値("2025-09-18")」ではなく「値(value)」と「タイプ(type)」の連想配列が取得できてしまう。
これでは意味がない。
加えていちゃもんを挙げるのであれば、中間キーも候補に挙がるため、選択したいフィールドを探すこと自体が大変であるというのもデメリットだ。
改善案2. 「選択」+「JSONの解析」アクションを利用する
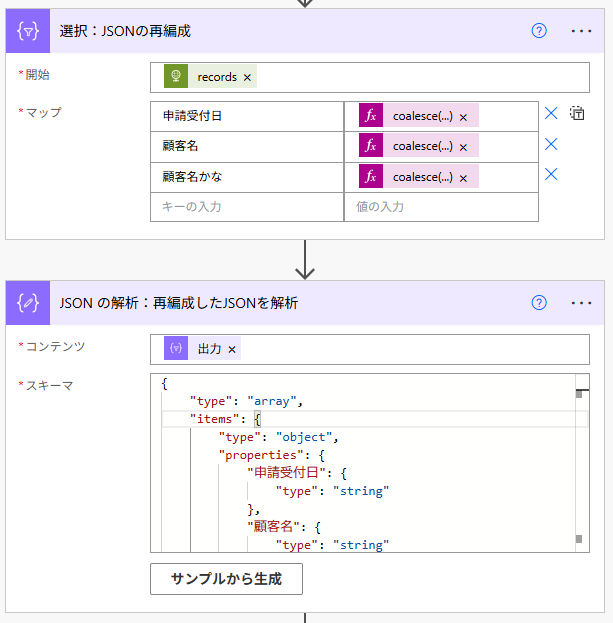
まず、「選択」アクションで階層1のJSONに再編成する。
■開始
@{body('HTTP:Kintoneのレコードを複数取得する')['records']}
■マップ
coalesce(item()?['order_received_date']['value'],'')
coalesce(item()?['client_name']['value'],'')
coalesce(item()?['client_name_kana']['value'],'')
選択後の出力結果が階層1になり非常に見やすくなった(問題2の解決)
[
{
"申請受付日": "2025-09-18",
"顧客名": "合名会社錦浦舘",
"顧客名かな": "はっとり はなえ"
}
]
次に、再編成したJSONに対して「JSONの解析」アクションを使用する
上記JSONをコピーし、サンプルから生成により、スキーマを構築できる
これで、動的なコンテンツ上からもフィールドを選択できるようになった。(問題1の解決)
■コンテンツ
@{body('選択:JSONの再編成')}
■スキーマ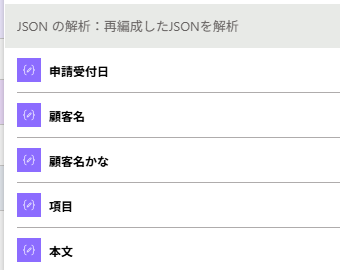
これで、問題点1, 2が解決したが、まだ問題点3が残っている。
結局のところ、Kintoneからレコードを取得するフローの数だけ「選択」と「JSONの解析」の2アクションを配置しなければいけない。
2アクションだけなので、修正が発生しても手間ではないという気持ちも分からないではないが、そこそこに大きめの規模のプロジェクトで10 ~ 20か所に同じアクションを配置しており、その数だけ修正が必要だと考えたら、なかなか辛いものがある。
また、これはプログラミングで言うところの、同じ処理をメソッドにせず、コピペされている状態に等しい。コピペダメ絶対。
ということで、改善?したのが改善案3である。
改善案3. 「子フロー」をオブジェクトとして扱う
子フローの処理
テキスト化されたJSON形式のレコードを引数として受け取る (JSON ⇒ テキスト)
子フローではオブジェクト(JSON、配列)を直接受け取ることが出来ず、一度テキストに変換しなければならない- JSONParsedKintoneレコードで
テキスト化された引数をもう一度JSON形式に戻している (テキスト ⇒ JSON) - 「Power appまたはフローに返却する」アクションで、各フィールド毎に戻り値を設定する
ここでは、改善案2の「選択」+「JSON解析」を使って、再編成したJSONを親フローに返却することはできない。
子フローは戻り値にもオブジェクトを指定することはできないし、たとえ指定できたとしても、再度親フロー側で「JSONを解析」アクションを呼ばなければならず、二度手間が発生し、子フローを呼んだメリットがなくなってしまうからだ。
子フローの定義
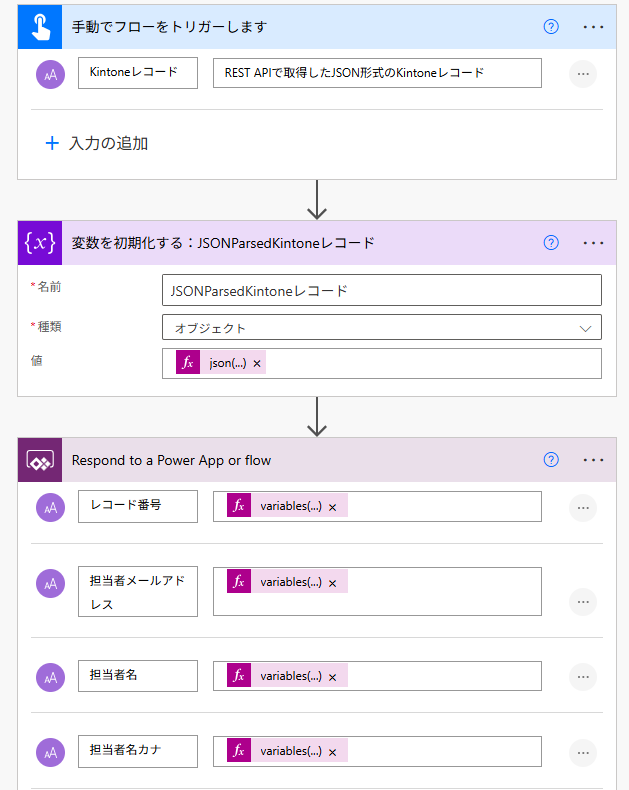
フィールド名が改善案2と違うのは、気にせんでくささい。
■変数を初期化する
@{json(triggerBody()['text'])}■Respond to a Power App or Flow
@{coalesce(variables('JSONParsedKintoneレコード')?['レコード番号'/'value'], '')}
@{coalesce(variables('JSONParsedKintoneレコード')?['担当者メールアドレス'/'value'], '')}
@{coalesce(variables('JSONParsedKintoneレコード')?['担当者名'/'value'], '')}
@{coalesce(variables('JSONParsedKintoneレコード')?['担当者名カナ'/'value'], '')}
親フローの定義
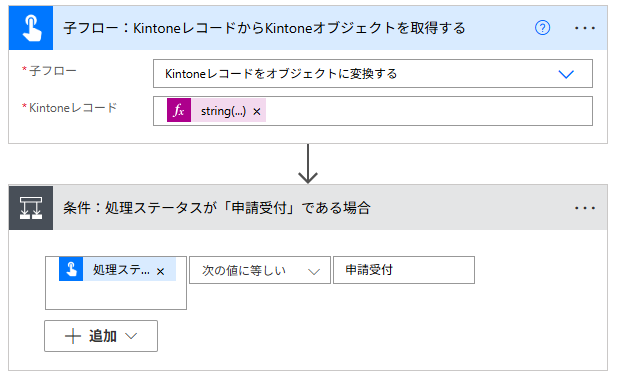
■子フロー呼び出し
// for each内でkintoneレコード1件分を、string()で変換している
@{string(items('ループ:Kintoneのレコード件数'))}
戻り値の参照
当然、子フローでフィールド別に値を返しているので、「JOSNの解析」をせずにそれぞれのフィールドにアクセスをすることができる。

改善案1 ~ 3のまとめ
| できること | メリット | デメリット | |||||
| 1 | 2 | 3 | |||||
| GUIから指定 | アクセスの容易さ | JSON構造変更への耐性 | |||||
| 改善案 | 1 | JSONの解析 | ○ | × | × | 実装が容易 | ・キー名重複に弱い ・複雑なJSON構造に弱い |
| 2 | 選択 + JSONの解析 | ○ | ○ | ○ | 処理が高速 | 変更に弱い | |
| 3 | 子フロー | ○ | ○ | ○ | 変更に強い | 処理が低速 子フローの実装が少し手間 |
|
子フロー呼び出しに伴う処理時間の目安
フィールドを10個持つKintoneレコード1件にかかる子フローの処理時間は0.25秒である。
ぶっちゃけかなり遅いので、その処理時間に耐えうる小規模なプロジェクトであれば改善案3を、そうでなければ改善案2を選択するとよい。