もくじ
はじめに
前記事「Azure AI Searchで最小のインデックスを作成する」で、最小構成のインデックスにはidフィールドしか設定されないことを確認した。RAGではドキュメント内のテキスト(content)をインデックスに格納しないことには、そもそもの検索が出来ない。また、テキストだけでなく、ファイル名やファイルの作成期間などのメタデータを用いると、検索の手段が増えてより便利である。
本記事では、contentおよびメタデータを追加していく。
設定項目
インデックスに列を増やす場合、次の3つの設定が必要である
インデックス
・新規フィールドを追加する
インデクサ―
・outputFieldMappingsの定義を追加する(※1, 2)
スキルセット
・インデックスに出力する情報を加工するための処理
コンテンツとメタデータの抽出だけを行う場合、インデックスの設定だけでよい。
(インデクサ―とスキルセットの設定は不要)
抽出条件について
contentの追加(※3)
ドキュメントのテキスト コンテンツが、”content” という名前の文字列フィールドに抽出されます。 標準およびユーザー定義のメタデータを抽出することもできます。
メタデータの追加(※3)
ユーザーが指定したメタデータ プロパティは、そのまま抽出されます。 値を受け取るには、
Edm.String型の検索インデックスに、BLOB のメタデータ キーと同じ名前のフィールドを定義する必要があります。
次に示すように、標準の BLOB メタデータ プロパティは、同じような名前のフィールドおよび型指定されたフィールドに抽出できます。 BLOB インデクサーでは、これらの BLOB メタデータ プロパティの内部フィールド マッピングを自動的に作成し、ハイフンが付きの元の名前 (“metadata-storage-name”) を下線付きの同等の名前 (“metadata_storage_name”) に変換します。
インデックス定義にアンダースコア付きフィールドを追加する必要がありますが、インデクサーによって関連付けが自動的に行われるため、フィールド マッピングを省略できます。
なお、ファイルごとに抽出できるメタデータの種類が変わってくるらしい。
ファイルごとのメタデータの一覧については(※4)参照
インデックスの設定(セットアップ画面を利用しない)
インデックスの作成
contentとmetadata_xxのフィールドを追加したインデックスを作成する
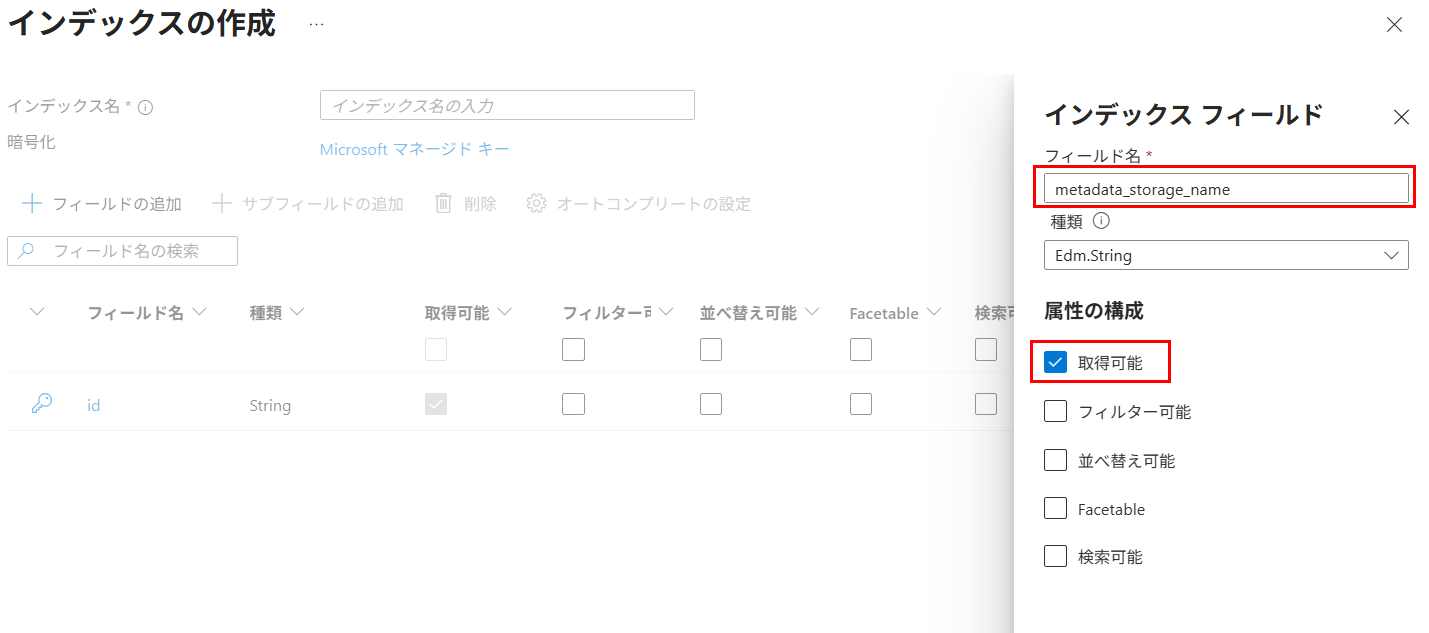
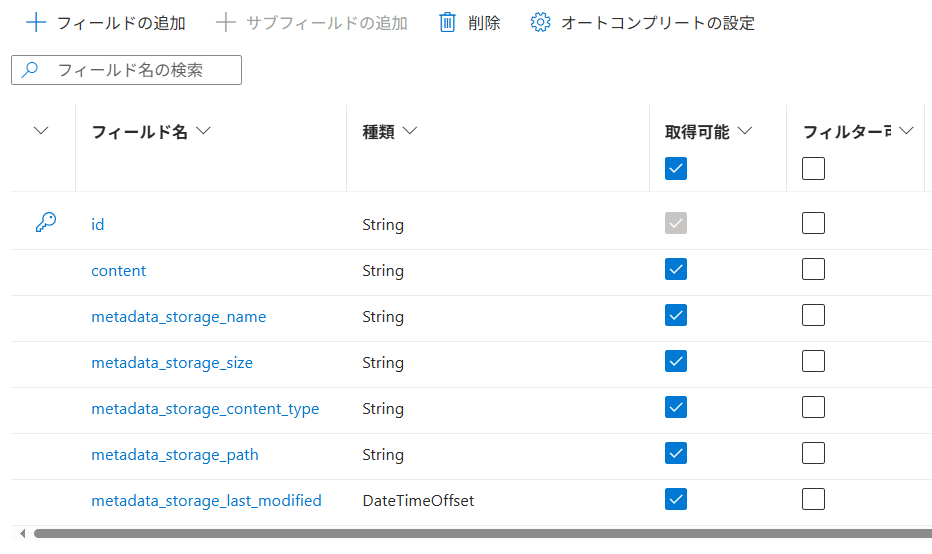
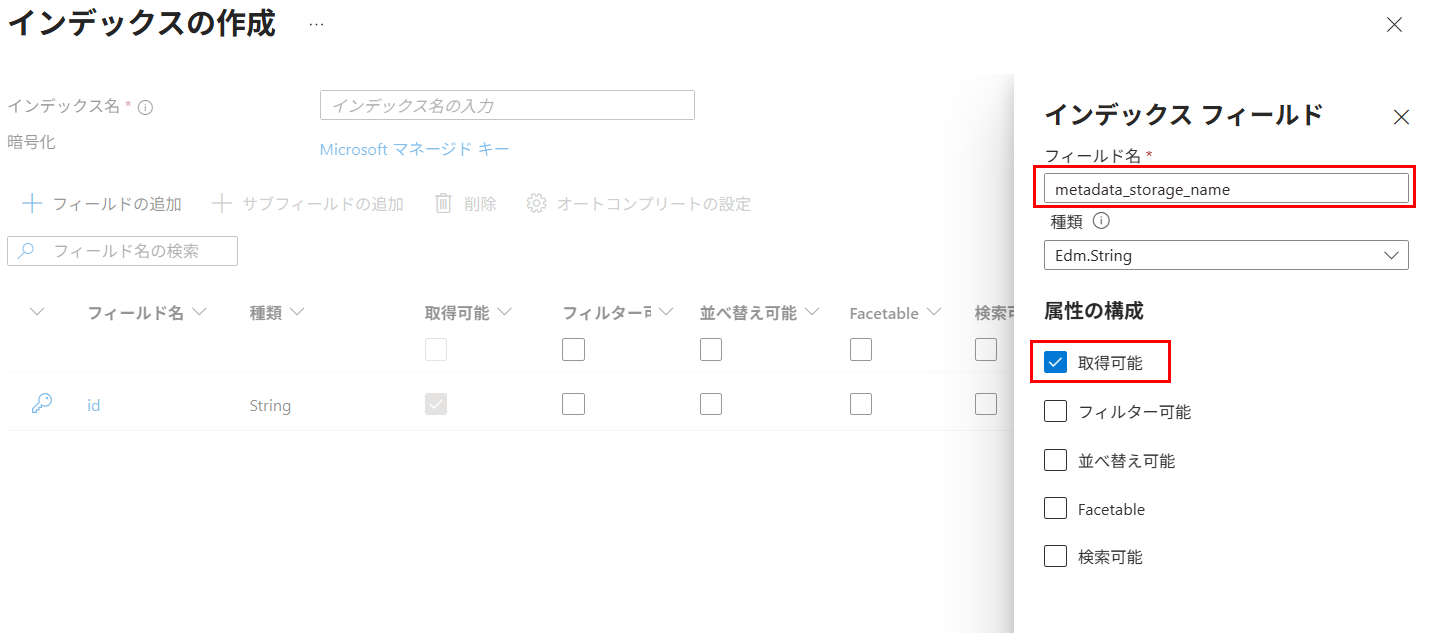{kind=link}
インデックスの格納データ
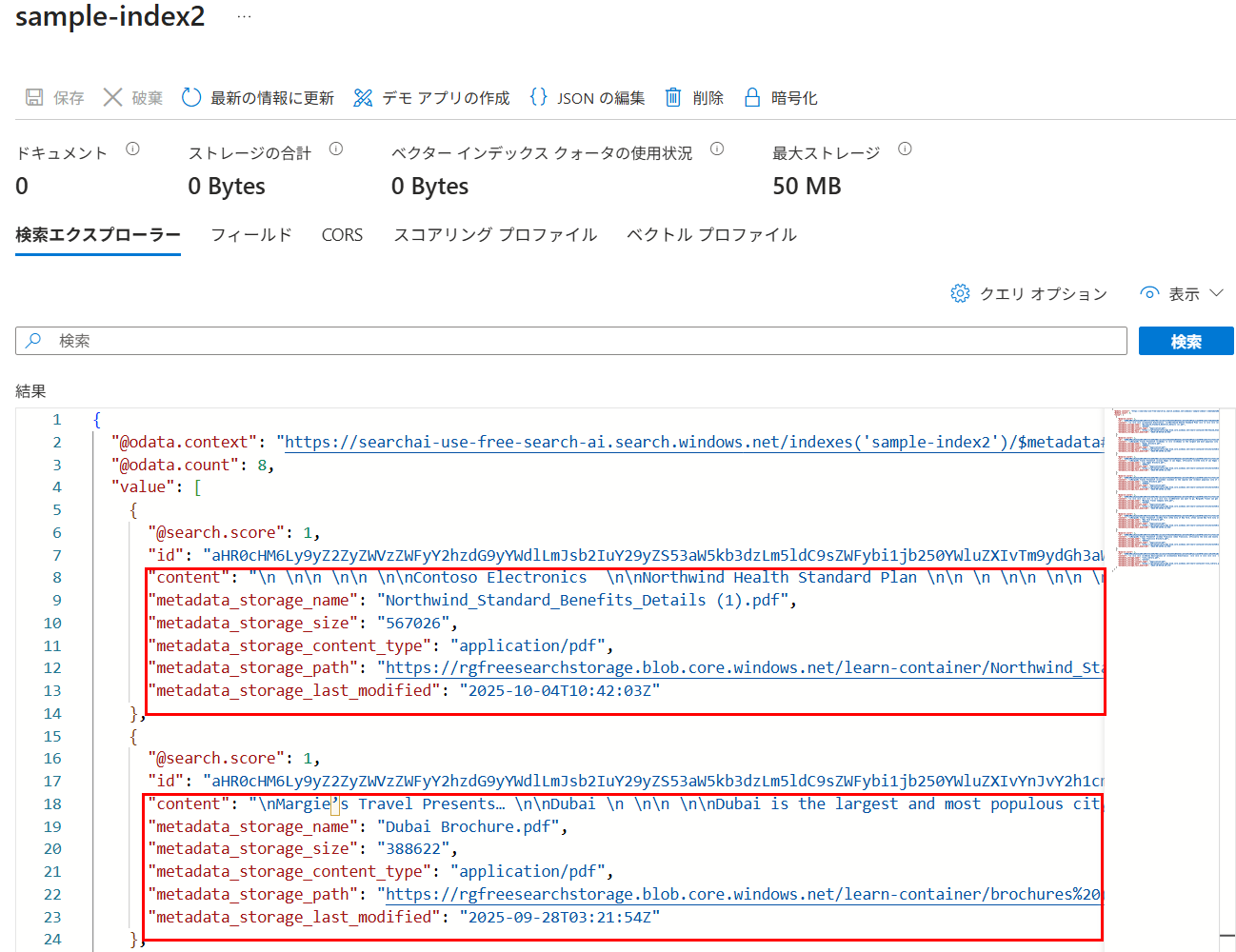
追加したフィールドにきちんと情報が格納されていることを確認できた。
contentも分かりづらいが、pdfファイル内の先頭のテキストが表示されている。
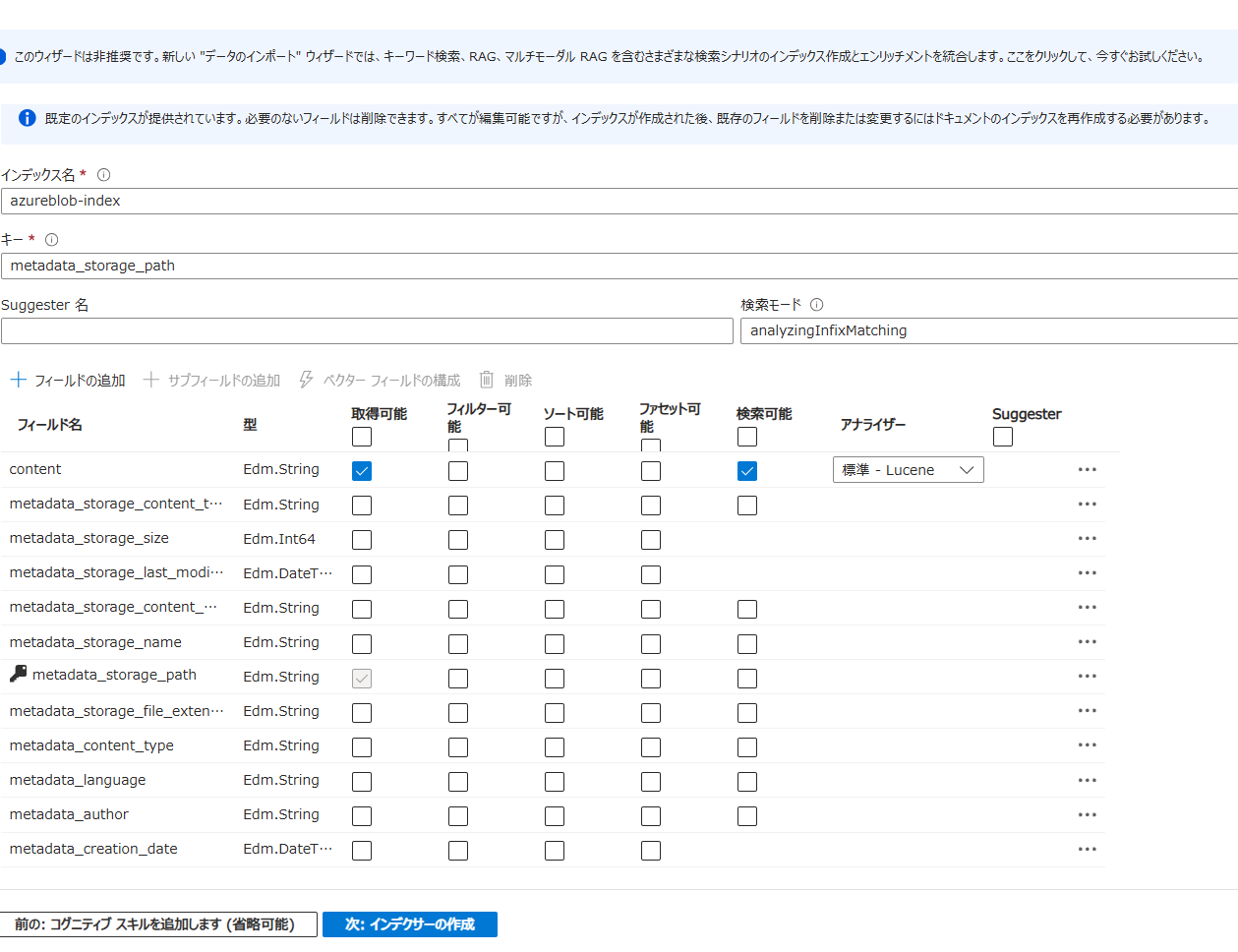
インデックスの設定(セットアップ画面を利用する)
セットアップ画面を利用する場合は、わざわざメタデータ用のフィールドを追加する必要がない。
セットアップ画面を表示するには、AI Searchの概要画面からインポートボタンをクリックする。

セットアップ中の画面、初期表示で全てのメタデータがあらかじめ追加された状態で、インデックスの作成画面が表示される。
参考サイト
- (※1) Azure AI Search のドキュメント > 操作方法ガイド > インデックス作成および情報強化パイプライン > スキルセット > インデックスのフィールドのマップする
エンリッチされた出力を検索インデックスのフィールドにマップする – Azure AI Search | Microsoft Learn - (※2)Azure AI Search のドキュメント > 操作方法ガイド > インデックス作成および情報強化パイプライン > スキルセット > スキル出力を参照する
スキルセットの実行中にエンリッチされたノードを参照する – Azure AI Search | Microsoft Learn - (※3)Azure AI Search のドキュメント > 操作方法ガイド > インデックス作成および情報強化パイプライン > データソース(インデクサー) > Azure Storage > Blobs
Azure BLOB インデクサー – Azure AI Search | Microsoft Learn - (※4)Azure AI Search のドキュメント > 操作方法ガイド > インデックス作成および情報強化パイプライン > インデクサー > ファイル全体のインデックス作成 > コンテンツメタデータプロパティ
コンテンツ メタデータ プロパティ – Azure AI Search | Microsoft Learn