もくじ
はじめに
前記事「Azure AI Searchのインデックスにフィールドを追加する(content、メタデータ編)」では、スキルセットを使わずに、フィールドをの追加を行った。
本記事ではスキルセットを使って、新たにインデックスにフィールドをしていく。
スキルセットとは(※1)
- ドキュメントを加工して新たなフィールドをインデックスに出力することができる
- スキルセットは1つ以上のスキルから構成される。
- スキルは順列につなぐこともできる。(スキル1の出力結果をスキル2の入力に利用する)
スキルセットの種類(※2)
スキルセットには下記4種類がある
1. 組み込みスキル
Microsoftがあらかじめ用意したスキルで、簡単に利用することができる反面、細かいカスタマイズは行うことが出来ない。
Open AIリソースへのモデルのデプロイは不要。
2. Open AIスキル
AIモデルに接続して、モデルからの応答を出力とする。
Open AIリソースへのモデルのデプロイが必要。
3. カスタムスキル
Azure Functionなどを通してデータソースを加工することができる。プログラムを実行させるわけだから、制限なく、理論上どのような加工でも可能である。
ただし、Azure Functionのリソースなど、別途準備・手間がかかる。
4. ユーティリティ
ドキュメントのテキスト分割
AIを使わずとも利用できる処理。
組み込みスキルの例(※2)
Microsoft.Skills.Text.TranslationSkill
このスキルは、正規化やローカライズのユース ケースにおいて、事前トレーニング済みのモデルを使用して入力テキストをさまざまな言語に翻訳します。
Microsoft.Skills.Text.V3.EntityRecognitionSkill
このスキルでは、トレーニング済みモデルを使用し、
"Person"、"Location"、"Organization"、"Quantity"、"DateTime"、"URL"、"Email"、"PersonType"、"Event"、"Product"、"Skill"、"Address"、"Phone Number"および"IP Address"の各フィールドのカテゴリの固定したセットに対してエンティティを確立します。
(i). 組み込みスキルの作成(セットアップ画面を利用しない)
今回はテキスト翻訳「TranslationSkill」とキーフレーズ抽出「EntityRecognitionSkill」の2つのスキルを作成する
(i-1). インデックスの作成
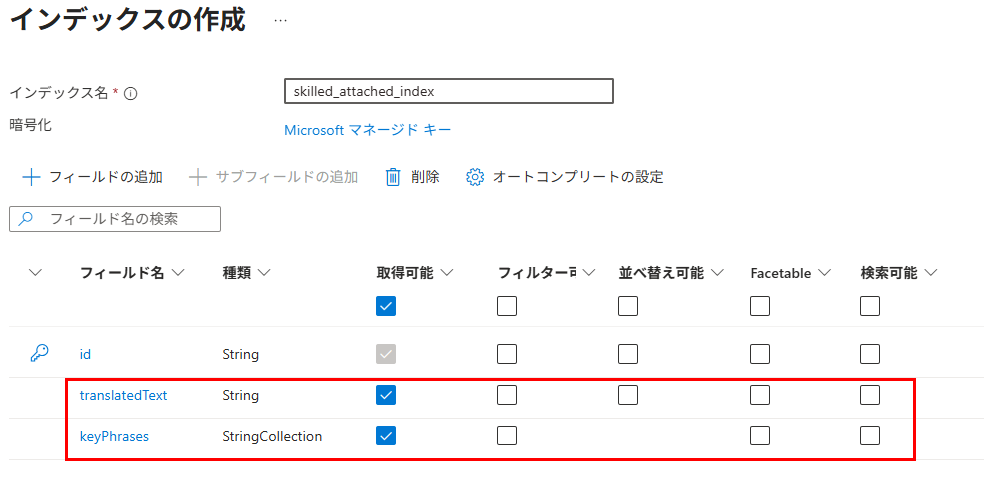
「translatedText」と「keyPhrase」の2つのフィールドを追加して、インデックスを作成する。
(i-2). スキルの作成
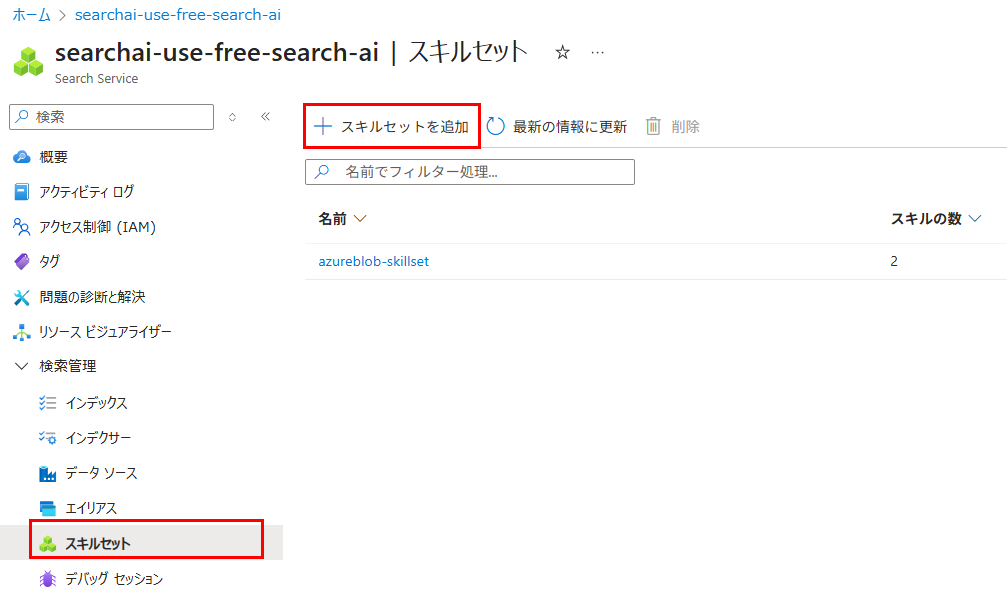
AI Searchリソース管理画面から、「+ スキルセットを追加」を押下
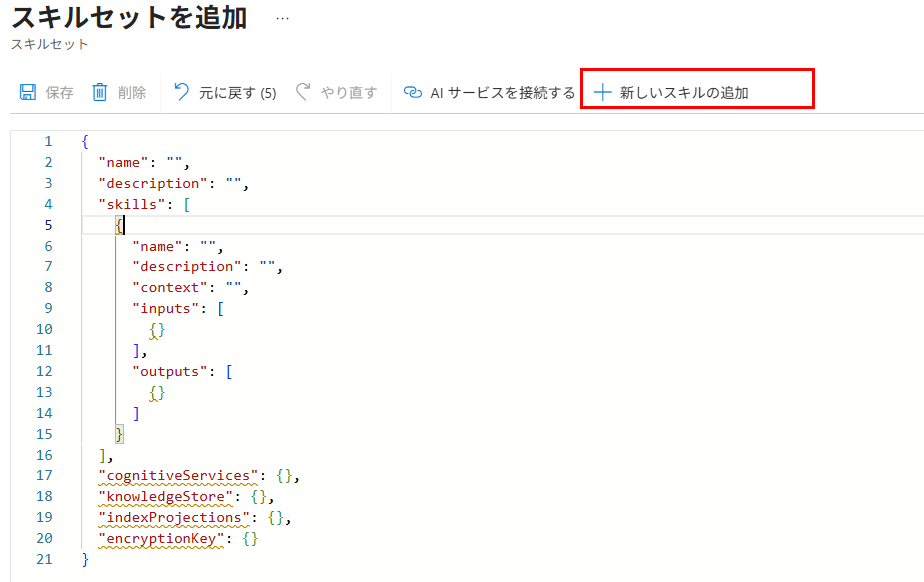
スキルセット編集画面が表示されたら、「+ 新しいスキルの追加」を押下
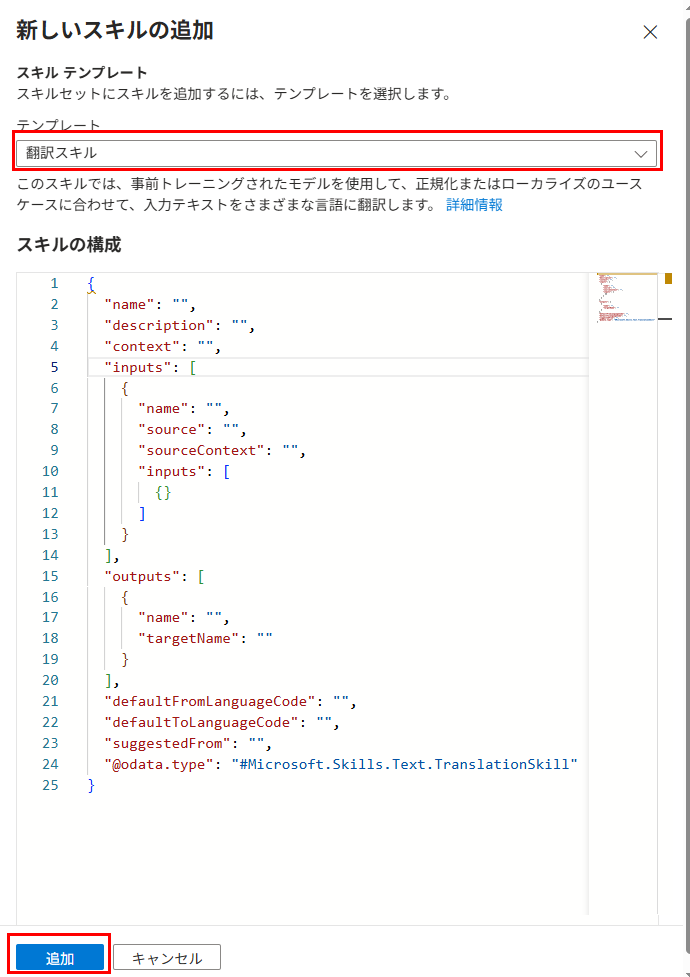
テンプレートから「翻訳スキル」を選択し、「追加」を押下。
同じ手順で「キーフレーズ抽出スキル」を選択し、「追加」を押下。
それぞれのスキルに対して、以下のようにパラメータを設定。
どのように設定をすべきかは公式リファレンスを確認する必要がある。
context, input/source
ドキュメントのどの範囲を入力とするか。
/documentから始まるパスを指定するのだが、ファイル中のテキストを参照したい場合 /document/contentを指定する。
(※5 入力の定義)
inputs
nameプロパティは公式リファレンス(※3, 4)で定義された文字列を指定しなければならない
outputs
nameプロパティは公式リファレンス(※3, 4)で定義された文字列を指定しなければならない
targetNameプロパティはスキルマップ内で利用される変数名であり、任意の文字列を設定できる。
{
"name": "sample-skill",
"description": "2つのスキルを利用します",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.TranslationSkill",
"name": "translate-skill",
"description": "テキストの翻訳を行います",
"context": "/document/content",
"inputs": [
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "translatedText",
"targetName": "translatedText"
}
],
"defaultToLanguageCode": "ja",
"suggestedFrom": "en"
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"name": "get-keyphrases-skill",
"description": "テキストからキーフレーズを抽出します",
"context": "/document/content",
"inputs": [
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
],
"maxKeyPhraseCount": 20
}
]
}
(i-3). outputFiledMappingの定義
スキルセットの出力結果とインデックスのフィールドを紐づける必要がある。
具体的にはスキルセットの「outputs/targetName」とインデックスのフィールド名を対応させる必要がある。
紐づけはインデクサーのoutputFieldMappingに定義する。
"outputFieldMappings": [
{
"sourceFieldName": "/document/content/translatedText",
"targetFieldName": "translatedText"
},
{
"sourceFieldName": "/document/content/keyPhrases",
"targetFieldName": "keyPhrases"
}
]
sourceFieldNameのパスについて
エンリッチされたドキュメント内のノードへのパスです。スキルの出力です。パスは常に /document で始まり、BLOB からインデックスを作成する場合、パスの 2 番目の要素は /content です。3 番目の要素は、スキルによって生み出される値です。
(i-4). インデックス作成結果の確認
残念ながらインデクサー作成時点で自動でインデックスが作成されてしまうため、インデクサを作成後にデータソース(Azure BLOB)に追加でファイルを追加する必要がある。インデックスの検索画面より、インデックスに翻訳テキストおよび、キーフレーズの抜粋ができていればOK
(ⅱ). 組み込みスキルの作成(セットアップ画面を利用する)
(i)では「インデックス」「インデクサー」「スキルセット」を手動で作成した。正直言ってとても手間である。
セットアップ画面ではボタンをポチポチするだけで、簡単に組み込みスキルを作成することができる。
AI Search の概要画面から「インポート」を押下
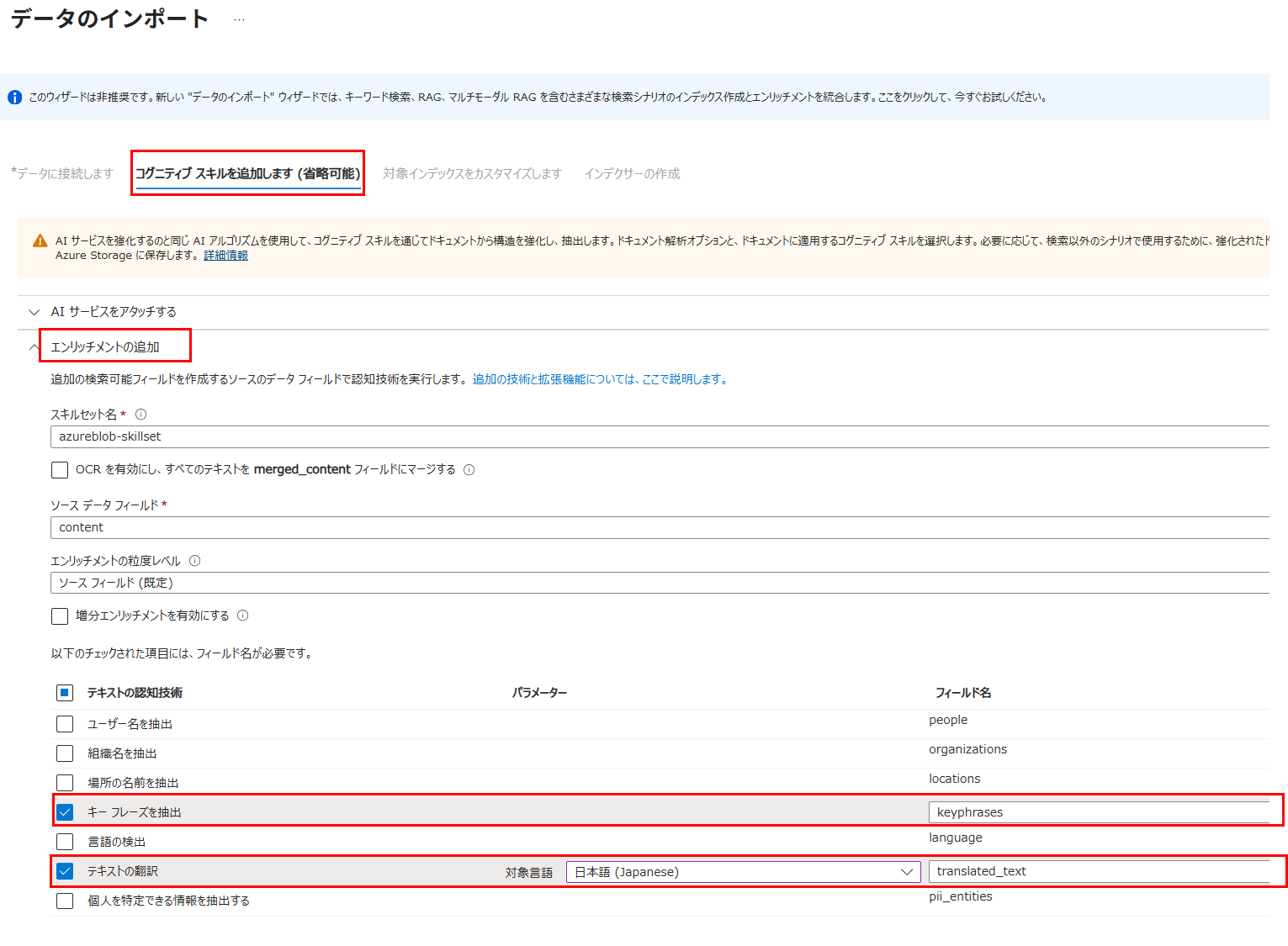
データのインポート画面にて「コグニティブスキルを追加します」> 「エンリッチメントの追加」から
利用したいスキルにチェックを入れる
まとめ
- スキルセット(組み込みスキル)を利用することで、AIを利用して抽出した情報をインデックスの新しいフィールドとして追加することができる。
- 出力したスキルセットは
outputFieldMappingで紐づけを行う必要がある - スキルセットのパラメータを細かくカスタマイズしないのであれば、セットアップ画面から作成したほうがとっても楽。
参考サイト
- ※1 Azure AI Searchのドキュメント > 操作方法ガイド > インデクサーとエンリッチメントパイプライン > スキルセット(インデックス)> スキルセットの概要
Azure AI Searchでのスキルセットの概念
Skillset concepts – Azure AI Search | Microsoft Learn - ※2 Azure AI Searchのドキュメント > リファレンス > スキルのリファレンス > Overview
インデックス付け中に追加処理を行うスキル (Azure AI Search)
スキルのリファレンス – Azure AI Search | Microsoft Learn - ※3 Azure AI Searchのドキュメント > リファレンス > スキルのリファレンス > Azure AI スキルのリソース > テキスト翻訳
テキスト翻訳コグニティブ スキル
テキスト翻訳コグニティブ スキル – Azure AI Search | Microsoft Learn - ※4 Azure AI Searchのドキュメント > リファレンス > スキルのリファレンス > Azure AI スキルのリソース > キーフレーズ抽出
キー フレーズ抽出コグニティブ スキル
キー フレーズ抽出コグニティブ スキル – Azure AI Search | Microsoft Learn - ※5 Azure AI Searchのドキュメント > 操作方法ガイド > インデクサーとエンリッチメントパイプライン > スキルセット(インデックス)> スキルセットを作成する
Azure AI Search でスキルセットを作成する
スキルセットを作成する – Azure AI Search | Microsoft Learn - ※6 Azure AI Searchのドキュメント > 操作方法ガイド > インデクサーとエンリッチメントパイプライン > スキルセット(インデックス)> インデックスフィールドへのマップ
インデックスフィールドへのマップ
エンリッチされた出力を検索インデックスのフィールドにマップする – Azure AI Search |Microsoft Learn