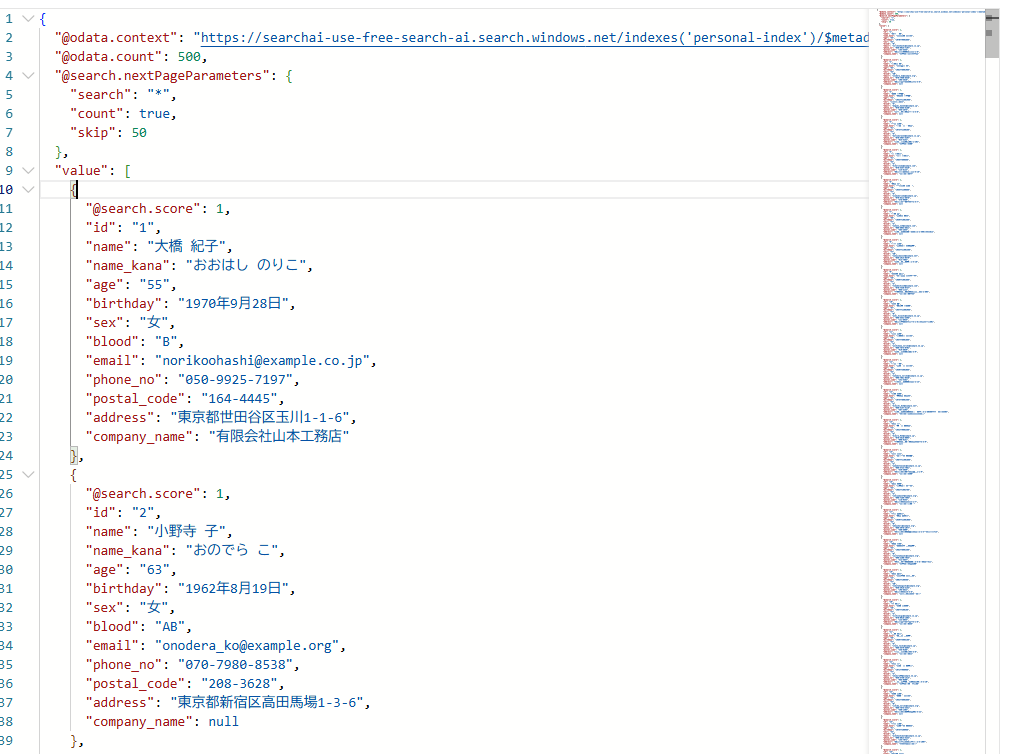
やりたいこと
csvファイルの各列をフィールドに持つようなインデックスを作成したい
※以下は架空の個人データです

セットアップ画面からは作成不可(余談)
セットアップ画面上でも解析モードがあるため、csvファイルの一括インポートが出来そうに見えるが…
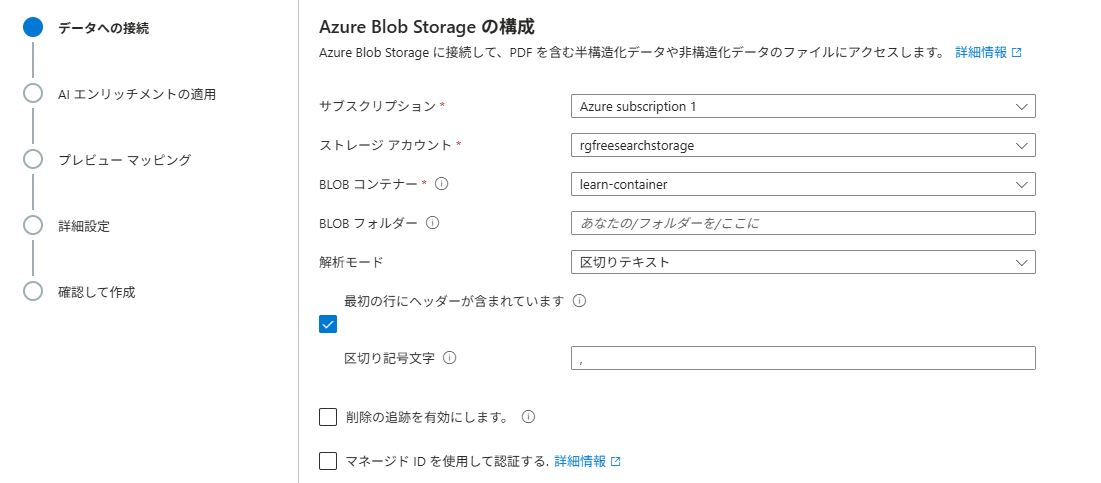
インデックスフィールドの編集画面にて、主キーは「metadata_storage_path」から変更することが出来ない。
これにより、何が起こるかというと
インデックス作成時、以下のエラーが発生する
原文
‘This indexer is configured for a one-to-many parsing mode. The index key is also mapped from property ‘metadata_storage_path’_ which is a blob metadata property. These two configurations are in conflict. Please either change the parsing mode, or what field maps to the index key field.’
日本語訳
このインデクサは「1対多 (one-to-many) の解析モード」に設定されています。
しかし、インデックスのキーがmetadata_storage_path(Blobのメタデータ項目)にマッピングされています。
この2つの設定は互いに矛盾しています。
解析モードを変更するか、インデックスキーとしてマッピングしているフィールドを変更してください。
つまり、metadata_storage_pathを主キーに設定しているけれど、同じファイルの各行に対するストレージパスなんて全部同じになるに決まっている。
ゆえに全行で主キーが重複してしまっているために表示されるエラーである。
これは、主キーを「metadata_storage_path」から変更しないと解決しないが、セットアップ画面上では、一意になりうるキーを選択することができないため、詰みである。
おとなしく、インデックスを個別に作成する必要がある。
インデックスの作成
csvのヘッダー行の項目名と一致するように、フィールドを追加する。
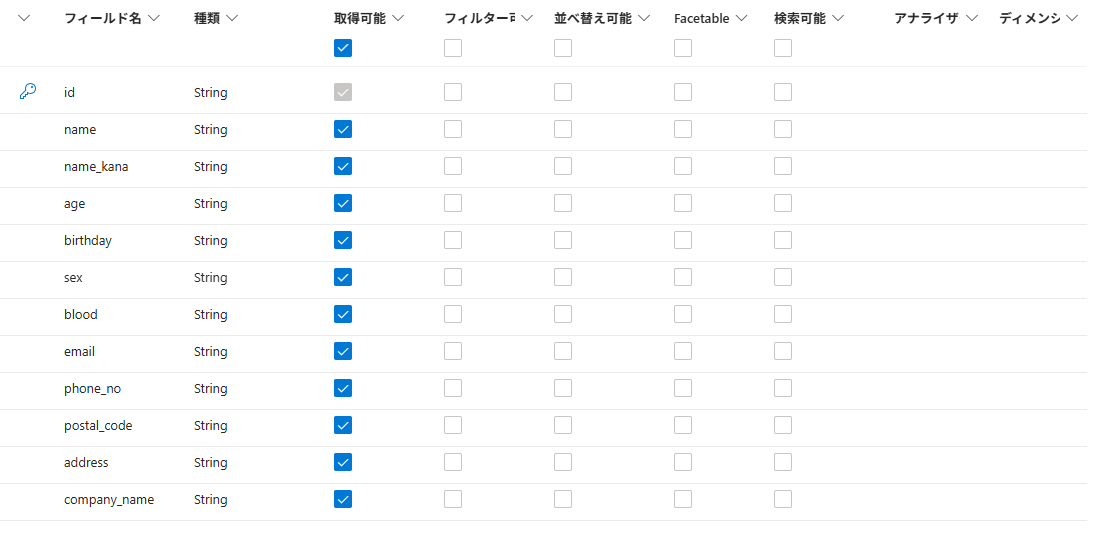
インデクサの作成
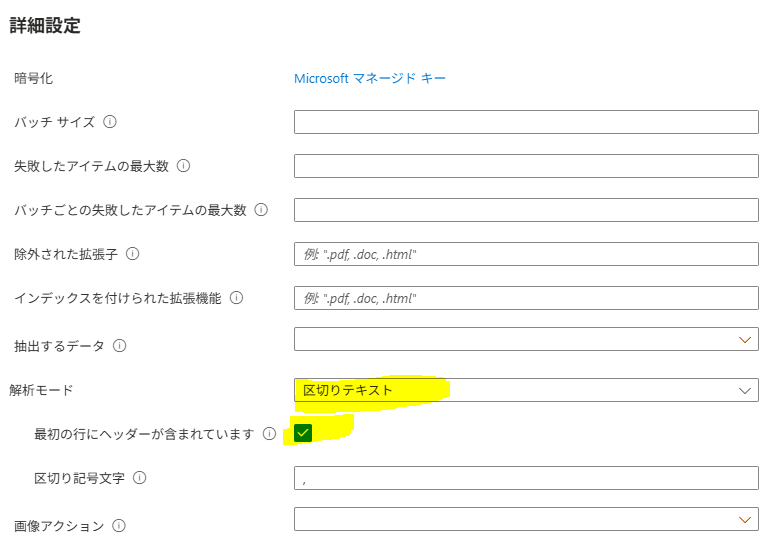
詳細設定にて、以下を設定する。
解析モード:「区切りテキスト」
最初の行にヘッダーが含まれています:true
区切り記号文字「,」
実行結果
csvファイルはBlob Storageに放り込んでいる。
インデックス > 検索エクスプローラ画面にて、きちんとインポートできていることを確認。