Power AutomateでSharepointのアクションを触れるにあたり、認識があやふやであったため整理する。
もくじ
ドライブID
ドキュメントライブラリとドライブIDの関係性について
- ドキュメントライブラリとドライブIDはイコールの関係である
- 1つのドキュメントに対して識別子であるドライブIDが割り当てられる
- ドライブIDは英数字の羅列である
- 1サイトに複数のドキュメントライブラリを持つことができる
Power Automateにおけるドキュメントライブラリの指定の仕方
- ライブラリ「ドキュメント」を選択候補から選択する
- 「ドキュメント」のドライブIDを指定する
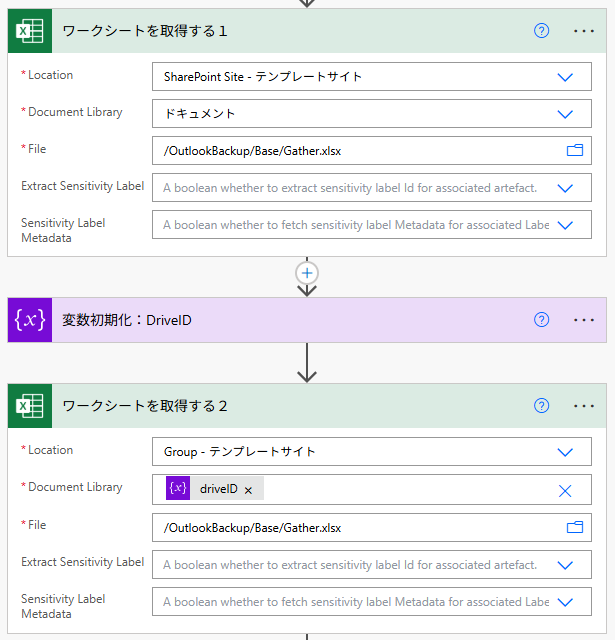
下記キャプチャの実行結果を確認すると、入力パラメータは文字列の「ドキュメント」ではなく「drive: (drive id の英数字の羅列)」が設定されていた。
また、文字列「ドキュメント」を手入力または変数として渡すと「不正なドライブです」とエラーが発生する。
つまり、画面上では日本語で設定しているように見えるが、実際には必ずdrive idを渡さなければいけないということである。
ファイル識別子
ファイル識別子の表記
結論から言うと、ファイル識別子≒ファイルパスである。
古い記事を確認すると以下の説明をちらほら見かける。
- ファイル識別子は「英数字の羅列」である
- ファイル識別子は「一意であり不変」である
しかし「ファイルのメタデータを取得する」アクションの出力結果ではId(ファイル識別子)はファイルパスに近しい表記になっている。
また、ファイルの移動後にもう一度アクションを実行すると、移動先のパスに沿う形でId(ファイル識別子)の文字列は変更されていた。
Chat GPTくんに聞いてみたところ、ファイル識別子の表し方に仕様変更されたようだ。
🕰 昔の仕様(古めの記事)
SharePoint のファイルはライブラリ内の「リストアイテム」として扱われていた
そのため「ファイルID = アイテムID(数値、例:1234)」で一意に識別していた
Power Automate でも当初は
Get itemなどのアクションと同様に、数字のIDでアクセスする設計が主流🧱 現在の仕様(2022年頃~)
Power Automate の SharePoint アクションは「ファイル識別子」に
ServerRelativeUrlに近いパスを使用これは「ファイルの位置情報」をベースとした識別で、可読性が高く、API的にも扱いやすくなった
裏では
"Identifier"という特殊なパス文字列が内部で使われている(ほぼServerRelativeUrl)✅ この仕様変更により、ファイルが移動されると識別子も変わるという現在の挙動が導入されました。
ファイル識別子 = ファイルパスであるか
結論から言うと、ファイル識別子≒ファイルパスであり、完全一致ではない。
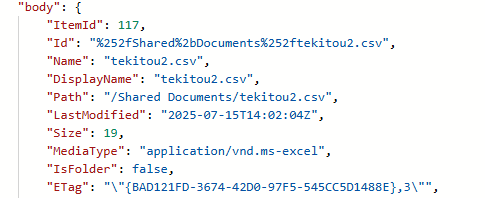
先ほどの「ファイルのメタデータを取得する」アクションの出力結果は以下であった。
ID: %252fShared%2bDocuments%252fOutlookBackup%252fBase%252ftekitou2.csv
Path:/Shared Documents/OutlookBackup/Base/tekitou2.csv
また、手動選択したファイルのパス(/区切り)は自動的にファイル識別子形式(%つき)に置き換わっているようだ。
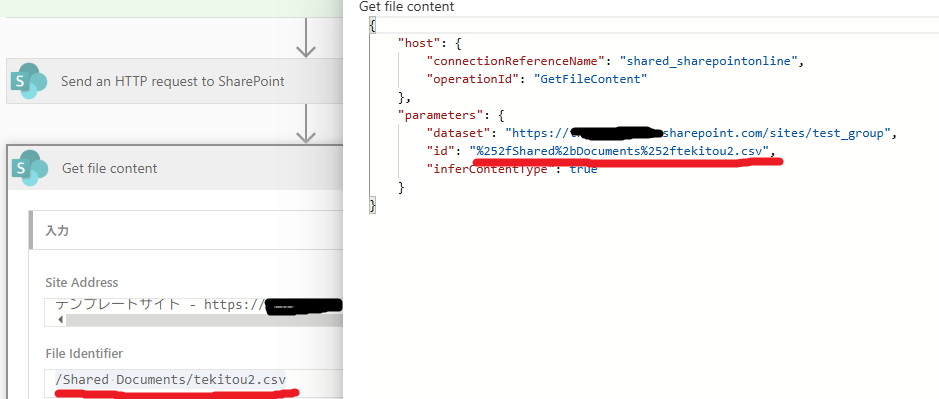
URLデコードのできるサイトを利用してみると以下のように変換されることが分かった。
-
%252fShared%2bDocuments%252ftekitou2.csv %2fShared+Documents%2ftekitou2.csv/Shared Documents/tekitou2.csv
デコードを2回行うことで、「%252F →%2f → /」「%2b → + → ␣」と変換された。
Power Automateにおけるファイル識別子の指定の仕方
ファイルパス → ファイル識別子として利用する場合、URLエンコーディングが2回必要
Microsoftによると、両者は同じ機能だけど、encodeUriComponent()でなくuriComponent()を使ってねという謎の説明がされている。(リンク)
@{uriComponent(uriComponent(variables('FilePath')))}ファイル識別子 → ファイルパスに変換する場合、URLデコーディングが2回必要
@{decodeUriComponent(decodeUriComponent(variables('URL')))}そもそもなぜ2回変換をする必要があるの?
URL中に文字列としての「%」が含まれていた場合、それがエスケープ文字としての%であるか、文字としての%であるか区別がつかないため、%自体もエンコードとして置き換える必要がある。(文字としての% → %25)
これ以上は沼りそうなので、とりあえずpower automateにおいては2回処理すれば問題ない程度で認識しておけば問題ない(と思われる)