もくじ
はじめに
Azure AI Searchではインデックスに対して複数の検索手段が用意されている。
- ベクトル検索
- エージェンティック検索
- フルテキスト検索
- ハイブリット検索
今回は、「フルテキスト検索」について整理していく。
フルテキスト検索とは
公式リファレンスの説明(※1)
まずは、Microsoftの公式リファレンスから説明を抜粋する。
フルテキスト検索は、インデックスに格納されているプレーン テキストと照合する情報取得のアプローチです。 たとえば、クエリ文字列 “hotels in San Diego on the beach” を指定すると、検索エンジンはそれらの用語に基づいてトークン化された文字列を検索します。
検索を理解するには、インデックス作成の基本をいくつかを把握しておくと役立ちます。 保存の単位は転置インデックスで、検索可能なフィールドごとに 1 つ存在します。 転置インデックス内には、全文書から抽出されたすべての語句を並べ替えたリストが存在します。 それぞれの語句は、それが出現する一連の文書に対応付けられています (以下の例を参照)。
転置インデックスに含める語句を得るために、検索エンジンは、クエリの加工時と同様の字句解析を文書の内容に対して実行します。
1.テキスト入力 は、アナライザーの構成に応じて、すべて小文字に変換され、句読点が削除されるなどの処理が行われます。
2.”トークン” は字句解析の出力です。
3.”用語” はインデックスに追加されます。
検索手法
通常、人間がドキュメントを検索する際、1つずつドキュメントを読み取って(開いて)その中から部分一致するキーワードを探し出すという工程をイメージする。実際のフルテキスト検索では、各ドキュメントを1つずつ読み取っているのではなく、単語(トークン)での検索を行う。例として、ホテル情報が蓄えられたインデックスで「景色のいい海辺にあるホテル」と検索した場合「景色のいい/海辺/ホテル」のような形で分割される。
分割されたトークンは転置インデックスに格納され、検索時にはドキュメントを直接検索するのではなく転置インデックスにある一致するトークンを検索し、そこからドキュメントを取得する。
ドキュメントや検索クエリからトークンへの変換はアナライザーが行ってくれる。
インデックス作成イメージ
例としてRPGゲームの紹介文を登録することを考える。入力データは以下の通り。
[
{
"id": "1",
"title": "ドラゴン・オデッセイ",
"description": "古代竜の封印を解くため、失われた王国を旅する壮大なRPG。多彩なジョブと奥深い戦闘システムが特徴。",
"price": 6800
},
{
"id": "2",
"title": "ドラゴン・クロニクル",
"description": "滅びた文明の遺跡に眠る伝説の竜を追う冒険者たちの物語。仲間との絆と選択が運命を変える。",
"price": 7100
},
{
"id": "3",
"title": "ドラゴン・サンクチュアリ",
"description": "竜の加護を受けた聖域をめぐる戦い。ドラゴン使いと呼ばれる者たちが世界の命運を握る。",
"price": 7200
},
{
"id": "4",
"title": "スカイリア・クロニクル",
"description": "空に浮かぶ群島を舞台に、空賊と帝国の戦いを描くスチームパンクRPG。飛空艇での探索と空中戦が魅力。",
"price": 7900
},
{
"id": "5",
"title": "フォーチュン・クロニクル",
"description": "運命のカードが導く未来を占う少女の物語。カードの力でドラゴンを召喚し、運命を切り開け。",
"price": 6200
},
]
アナライザーに通すことで、単語レベルに分解される。
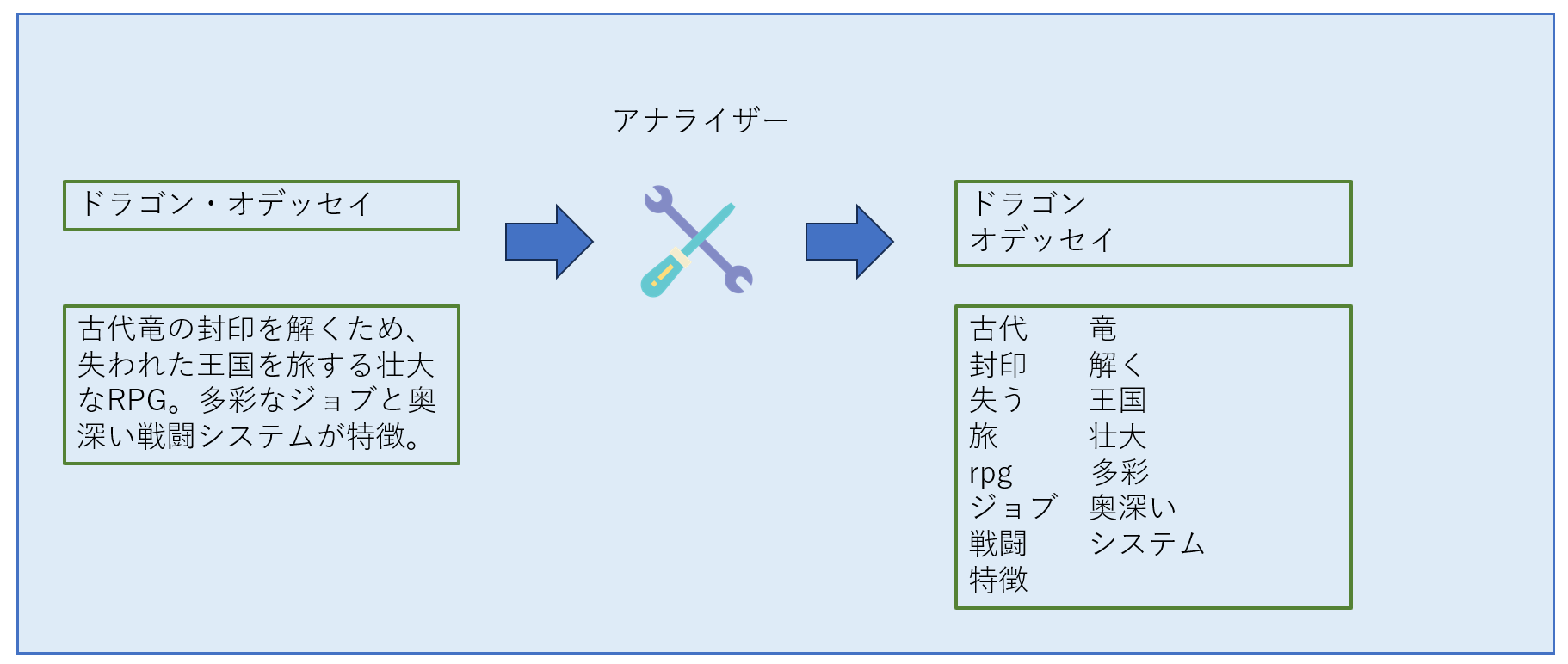
これを各ドキュメントごとに繰り返すことで、トークンとドキュメントの対応表であるフィールドごとに転置インデックスが作成される。
タイトルの転置インデックス
| トークン | ドキュメントID | 出現数 |
| ドラゴン | [1,2,3] | 3 |
| オデッセイ | [1] | 1 |
| クロニクル | [2,4,5] | 3 |
| サンクチュアリ | [3] | 1 |
| スカイリア | [4] | 1 |
| フォーチュン | [5] | 1 |
説明文の転置インデックス
| トークン | ドキュメントID | 出現数 |
| 竜 | [1, 2, 3] | 3 |
| rpg | [1, 4] | 2 |
| 者 | [2, 3] | 2 |
| 物語 | [2, 5] | 2 |
| 運命 | [2, 5] | 2 |
| 戦い | [3, 4] | 2 |
| ドラゴン | [3, 5] | 2 |
| 古代 | [1] | 1 |
| 封印 | [1] | 1 |
| 解く | [1] | 1 |
| 失う | [1] | 1 |
| 王国 | [1] | 1 |
| 旅 | [1] | 1 |
| 壮大 | [1] | 1 |
| 多彩 | [1] | 1 |
| ジョブ | [1] | 1 |
| 奥深い | [1] | 1 |
| 戦闘 | [1] | 1 |
| システム | [1] | 1 |
| 特徴 | [1] | 1 |
| 滅びる | [2] | 1 |
| 文明 | [2] | 1 |
| 遺跡 | [2] | 1 |
| 眠る | [2] | 1 |
| 伝説 | [2] | 1 |
| 追う | [2] | 1 |
| 冒険 | [2] | 1 |
| 仲間 | [2] | 1 |
| 絆 | [2] | 1 |
| 選択 | [2] | 1 |
| 変える | [2] | 1 |
| 加護 | [3] | 1 |
| 受ける | [3] | 1 |
| 聖域 | [3] | 1 |
| めぐる | [3] | 1 |
| 使い | [3] | 1 |
| 呼ぶ | [3] | 1 |
| 世界 | [3] | 1 |
| 命運 | [3] | 1 |
| 握る | [3] | 1 |
| ~~以下略~~ | ||
アナライザーについて
アナライザーの役割
- アナライザーは
Searchable(検索可能)が有効であるテキスト型フィールド(Edm.String、Collection(Edm.String))に対してのみ設定できる。 - アナライザーではテキストから
トークンへの変換時、以下の処理が行われる(※2)
- 重要でない単語 (ストップワード) と句読点を削除します
- フレーズやハイフンでつながれた単語を構成部分に分割します
- 大文字になっている単語があれば小文字に変換します
- ストレージの効率性のために単語をプリミティブな原形に単純化し、時制に関係なく一致を見つけられるようにする
1. ストップワード
ストップワードとは検索処理をする上で、重要ではない語句のこと。
英語の場合、「a, the , is 」など、日本語であれば、接続詞の「の を に は が と で」がストップワードに該当する。
ストップワードを削除しない場合、接続詞を持つドキュメント=ほぼすべてのドキュメントが検索の対象に引っかかってしまい検索の精度が落ちてしまうため、削除する必要がある。
ストップワードの一覧については(※3)を参照
4. 単語の原形化
失われた⇒失う、滅びた⇒滅びる、切り開け⇒切り開くのような変換をすることで、検索時の一致率をアップさせる
アナライザーと言語の選択
アナライザーにはいくつか種類があり、リファレンスにて確認可能だ(※4)
デフォルトでは言語に依存しない既定アナライザー (standard.lucene)が選択される。
既定アナライザーにはスペースやハイフン、スラッシュなどの記号ベースで単語を分割する。(※4)という特徴があり、日本語や中国語などの文中にスペースが入らない言語とはマッチしない。
試しに、既定アナライザー (standard.lucene)と日本語アナライザー (ja.lucene)でのトークン生成の違いを見てみよう。
インプットとするテキストは上記例と同じ「古代竜の封印を解くため、失われた王国を旅する壮大なRPG。多彩なジョブと奥深い戦闘システムが特徴。」を使用する。
- 規定アナライザー(standard.lucene)
古/代/竜/の/封/印/を/解/く/た/め/失/わ/れ/た/王/国/を/旅/す/る/壮/大/な/RPG/多/彩/な/ジョブ/と/奥/深/い/戦/闘/システム/が/特/徴/- 日本語アナライザー(ja.lucene)
古代/竜/封印/解く/失う/王国/旅/壮大/rpg/多彩/ジョブ/奥深い/戦闘/システム/特徴単語の分解結果が全く違うことが分かった。
既定アナライザー (standard.lucene)はほとんど1文字ずつ分割してしまい、使い物にならない。
テキストが日本語の場合、必ず日本語アナライザーを利用しなければならないことが分かる。
ja.luceneとja.microsoftの選択
アナライザーにはさらに、(言語).luceneと(言語).microsoftの2種類が用意されている。
違いは以下の通り(※4)
- エンティティの認識 (URL、メール、日付、数字) を高精度に抽出できる
- (言語によっては)インデックスの作成はmicrosoftの方が2~3倍時間がかかる可能性がある
- (平均的なサイズのクエリであれば)検索のパフォーマンスはさほど変わらない
これもまた両者を比較してみよう
利用するテキストは「注文番号No.20251004を確認。連絡はmail:test.user@contoso.comまたは電話090-1234-5678までお願いします。」である。
ja.lucene
注文/番号/no/20251004/確認/連絡/mail/test/user/contoso/com/電話/090/1234/5678/お願いja.microsoft
注文/番号/no.20251004/確認/連絡/mail/test.user@contoso.com/test/user/contoso/com/また/電話/090-1234-5678/090/nn90/1234/nn1234/5678/nn5678/まで/お願い/し/ますたしかにja.microsoftの方が、メールアドレスや電話番号を1つのトークンとして扱うことができている。
また、短文ではあるが、ja.luceneの方がストップワード(削除するワード)が多いように見受けられる。(また/まで/します)
アナライザーのREST API呼び出し
アナライザーがどのように単語分解するかをREST APIを使ってテストをすることができる。(※5)
■ URL
https://<AI SearchリソースのURI>/indexes/<インデックス名>/search.analyze?api-version=2025-08-01-preview
■ Header
{
"Content-Type": "application/json"
"api-key": "AI SearchリソースのAPIキー"
}
■Body
{
"text": "★単語分解したいテキスト★",
"analyzer":"ja.lucene"
}
まとめ
- Azure AI Searchではアナライザーが分解した単語(トークン)単位での検索処理が行われる
- アナライザーは言語ごとに性能が異なり、テキストが日本語である場合は、
ja.luceneまたはja.microsoftを必ず指定する ja.microsoftはja.luceneより、数字関連の抽出が得意だが、反面インデックス作成に時間がかかる場合がある
参考サイト
- ※1
Azure AI Searchのドキュメント > Concept > Retrieval > フルテキスト検索
Azure AI Search でのフルテキスト検索
フルテキスト検索 – Azure AI Search | Microsoft Learn - ※2
Azure AI Searchのドキュメント > ハウツーガイド > indexing > テキストのインデックスの作成 > Analyzers > アナライザーの概要
Azure AI Searchでのテキスト処理用のアナライザー
言語処理とテキスト処理のためのアナライザー – Azure AI Search | Microsoft Learn - ※3
Azure AI Searchのドキュメント > References > データ参照 > ストップワードのリファレンス
ストップワード リファレンス (Microsoft アナライザー)
ストップワード – Azure AI Search | Microsoft Learn - ※4
Azure AI Searchのドキュメント > ハウツーガイド > indexing > テキストのインデックスの作成 > Analyzers > 言語アナライザーの追加
Azure AI Search インデックスの文字列フィールドに言語アナライザーを追加する
言語アナライザーを文字列フィールドに追加する – Azure AI Search | Microsoft Learn - ※5
RESTの概要 > 検索サービス > References > Indexes > Analize
Indexes – Analyze
Indexes – Analyze – REST API (Azure Search Service) | Microsoft Learn